常识——人工智能打破意义障碍的关键

梅拉妮·米歇尔(Melanie Mitchell),波特兰州立大学计算机科学教授,曾在美国圣塔菲研究所(Santa Fe Institute)和洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory)工作,主要的研究领域为类比推理、复杂系统、遗传算法等。在圣塔菲研究所时,米歇尔主导了复杂系统领域的研究工作,并教授了相关的在线课程。她的在线课程 Introduction to Complexity 已有近30000名学生选修,成为Coursera排名前50位的在线课程之一。
人类天生具备一些核心知识,就是我们与生俱来的或很早就学习到的最为基本的常识。例如,即便是小婴儿也知道,世界被分为不同的“物体”,而且一个物体的各个组成部分会一起移动,同时,即便某一物体的某些部分在视野中看不见了,它们仍然是该物体的一部分。
(一)直觉
由于我们人类是一种典型的社会型物种,从婴儿时期开始我们逐步发展出了直觉心理:感知并预测他人的感受、信念和目标的能力。直觉知识的这些核心主体构成了人类认知发展的基石,支撑着人类学习和思考的方方面面。
(二)模拟
我们对于我们所遇到的情境的理解包含在我们在潜意识里执行的心智模拟中,这种心智模拟同样构成了我们对于那些我们并未直接参与其中的情境的理解,比如我们看到的、听到的或读到的。
(三)隐喻
我们通过核心物理知识来理解抽象概念。如果物理意义上的“温暖”概念在心理上被激活,例如,通过手持一杯热咖啡,这会激活更抽象、隐喻层面上的“温暖”概念,就像评价一个人的性格的实验那样,反之亦然。
(四)抽象与类比
构建和使用这些心智模型依赖于两种基本的人类本能:抽象和类比。抽象是将特定的概念和情境识别为更一般的类别的能力,类比在很多时候是我们无意识的行为,这种能力是我们抽象能力和概念形成的基础。
(五)反思
人类智能的一个必不可少的方面,是感知并反思自己的思维能力,这也是人工智能领域近来很少讨论的一点。在心理学中,这被称作“元认知”。
“我想知道人工智能是否以及何时能打破通向意义的障碍。”每次在思考人工智能的未来时,我就会回想起由数学家兼哲学家吉安-卡洛·罗塔提出的这个问题。“意义的障碍”(barrier of meaning)这一短语完美地捕捉到了贯穿于全书的一个思想:人类能够以某种深刻且本质的方式来理解他们面对的情境,然而,目前还没有任何一个人工智能系统具备这样的理解力。
尽管当前最先进的人工智能系统在完成某些特定的细分领域的任务上拥有比肩人类的能力,甚至在某些情况下的表现已经超越人类,但这些系统都缺乏理解人类在感知、语言和推理上赋予的丰富意义的能力。这一理解力的缺乏主要表现在以下方面:非人类式错误、难以对所学到的内容进行抽象和迁移、对常识的缺乏、面对对抗式攻击时所呈现出的脆弱性等。人工智能和人类水平智能之间的“意义的障碍”至今仍然存在。
在本章中,我将带你简要探究各领域的专家学者现在如何看待人类理解所涉及的内容,这些专家学者主要包括心理学家、哲学家和人工智能研究人员。下一章将描述在人工智能系统中,为使其获取人类理解方式构成要素,研究人员所做的一些重要工作。
• 理解的基石
想象你正驾车行驶在一条拥挤的城市街道上,当前的交通灯是绿灯,并且你正准备右转,前方却出现如图1所示的情境。作为一个人类驾驶员,你需要具备哪些认知能力来理解这一情境呢?
让我们从头开始说。人类天生具备一些核心知识,就是我们与生俱来的或很早就学习到的最为基本的常识。例如,即便是小婴儿也知道,世界被分为不同的“物体”,而且一个物体的各个组成部分会一起移动,同时,即便某一物体的某些部分在视野中看不见了,它们仍然是该物体的一部分,例如,图1中婴儿车后那位行人的脚。这就是一种不可或缺的常识!但是,即使给一个ConvNets大量的照片或视频数据来进行训练,它也未必能学会这些常识。
孩提时代,我们人类学习了大量关于世界上的物体如何运转的知识,在我们成年后,就完全将其视为理所当然,甚至意识不到自己具备这些知识。如果你推一个物体,它就会向前移动,除非它太重或者受到其他物体的阻挡;如果你扔下一个物体,它会落下,然后在接触到地面时会停住、弹起来或者破裂;如果你把一个较小的物体放在一个较大的物体后面,较小的那个就会被遮住;如果你把一个物体放在桌上然后将目光移开,那么除非有人故意移动该物体或者该物体能自行移动,否则当你看回来时,该物体仍将停留在原处。我们可以举出很多类似的例子。其中,非常关键的一点是:婴儿会发展出自己对世界上的因果关系的洞察力。例如,当有人推一个物体时,就像图1中的女士推着婴儿车,婴儿车的移动并非因为巧合,而是有人推它。
心理学家为此创造了术语“直觉物理学”(intuitive physics)来描述人类对物体及其运转规则所具有的基本知识。当还是孩童的时候,我们还发展出了“直觉生物学”(intuitive biology)的概念,用以区分生命体和非生命体。例如,任何一个小孩都明白,与婴儿车不同,图1中的狗能够自主移动或拒绝移动。我们有这样的直觉:狗和人类一样能听能看,它将鼻子贴在地面上是为了嗅某些东西。

由于我们人类是一种典型的社会型物种,从婴儿时期开始我们逐步发展出了直觉心理:感知并预测他人的感受、信念和目标的能力。例如,你能够从图1中了解到以下信息:图中的女士想要与她的孩子和狗一起穿过马路;她不认识迎面走来的男士,也不害怕他;她的注意力正集中在手机通话上;她希望同行的车辆能够为她让道,以及当她注意到车辆与她相距太近时,她会感到吃惊和害怕。
直觉知识的这些核心主体构成了人类认知发展的基石,支撑着学习和思考的方方面面。例如,我们能够从少数案例中学习到新的概念,并进行泛化,因此,我们才拥有了快速理解类似于图1中所示的情境并决定采取何种应对措施的能力。
• 预测可能的未来
理解任何情况,其本质是一种能够预测接下来可能会发生什么的能力。在图1的情境下,你预测正在过马路的人会继续朝着他们原来的方向行走;图中的女士将继续推着婴儿车、牵着狗,同时拿着手机。你也会预测:这位女士会拉一下狗绳,而那条狗会反抗,并想继续探索那个地方的气味,这位女士会更使劲儿地拉狗绳,然后这条狗会跟在她身后,走到马路上。如果你正在开车,你就需要为此做好准备!在一个更基本的层面上,你一定是希望女士的鞋子待在她脚上,头待在身体上,道路还固定在地面上。你预测那位男士会从婴儿车后面走出来,并且他将会有腿、脚和鞋子,这些会支撑着他站在路上。简而言之,你拥有心理学家所说的关于世界之重要方面的“心智模型”,这个模型基于你掌握的物理学和生物学上的事实、因果关系和人类行为的知识。这些模型表示的是世界是如何运作的,使你能够从心理上模拟相应的情况。神经科学家还不清楚这种心智模型或运行在其之上的心智模拟,是如何从数十亿相互连接的神经元的活动中产生的。一些著名的心理学家提出:一个人对概念和情境的理解正是通过这些心智模拟来激活自己之前的亲身经历,并想象可能需要采取的行动。
心智模型不仅能够让你预测在特定情况下可能会发生什么,还能让你想象如果特定事件发生将会引发什么。例如,如果你按车喇叭或从车窗向外大喊“从路上让开!”,这位女士可能会吓一跳,并将注意力转向你;如果她绊了一下,鞋子掉了,她会弯腰把鞋子穿上;如果婴儿车里的婴儿开始哭闹,她会看一眼出了什么事情。想要理解一个情境,其关键在于要能够利用心智模型来想象不同可能的未来。
• 理解即模拟
心理学家劳伦斯·巴斯劳(Lawrence Barsalou)是“理解即模拟”(understanding as simulation)假说最为知名的支持者之一。在他看来,我们对于我们所遇到的情境的理解包含在我们在潜意识里执行的心智模拟中。此外,巴斯劳提出,这种心智模拟同样构成了我们对于那些我们并未直接参与其中的情境的理解,比如我们看到的、听到的或读到的。巴斯劳写道:“当人们理解一段文本时,他们构建模拟来表征其感知、运动和情感等内容。模拟似乎是意义表达的核心。”
我可以轻易地想象出这样一个场景—— 一位女士在打着电话过马路时发生了车祸,并且通过我对这一情境的心智模拟来理解这件事。我可能会把自己代入这位女士的角色中,并通过我的心智模型所做的模拟来想象,我拿着手机、推着婴儿车、牵着狗绳、过马路、受到干扰等分别是什么感受。
对于像“真相” “存在” “无限”等这类非常抽象的概念,我们是如何理解的呢?巴斯劳和他的同事们几十年来一直主张:即便是最为抽象的概念,我们也是通过对这些概念所发生的具体场景进行心智模拟来理解的。
根据巴斯劳的观点,我们使用对感觉-运动(sensory-motor)状态的重演(即模拟)来进行概念处理,并以此来表征其所属类别,即使是对最抽象的概念也是如此。令人惊讶的是(至少对我来说):这一假说最具说服力的证据来自对隐喻的认知研究。
• 我们赖以生存的隐喻
很久以前,在一堂英语课上,我学习了“隐喻”的定义,其大致内容如下:
隐喻是一种以并不完全真实的方式来描述一个物体或动作,但有助于解释一个想法或做出一个比较的修辞手法……隐喻经常应用在诗歌等文学体裁上,以及人们想要为其语言增添一些文采的时候。
我的英语老师给我们列举了一些隐喻的例子,包括莎士比亚最著名的诗句:
“那边窗户里亮起的是什么光?那是东方,朱丽叶就是太阳。”
“人生不过是一个行走的影子,一个舞台上指手画脚的拙劣的伶人,登场片刻,就在无声无息中悄然退下。”
我当时的认识是:隐喻只不过是用来为原本平淡无奇的作品增添一些文采罢了。
许多年后,我读了由语言学家乔治·莱考夫(George Lakoff)和哲学家马克·约翰逊(Mark Johnson)合著的《我们赖以生存的隐喻》(Metaphors We Live By)一书,之后,我对隐喻的理解完全改变了。莱考夫和约翰逊的观点是:不仅仅是我们的日常语言中充斥着我们意识不到的隐喻,我们对基本上所有抽象概念的理解都是通过基于核心物理知识的隐喻来实现的。莱考夫和约翰逊引用了大量的语言示例来证明他们的论点,展示了我们如何用具体的物理概念来概念化诸如时间、爱、悲伤、愤怒和贫穷等抽象概念。
例如,莱考夫和约翰逊指出,我们会使用具体的概念,如金钱,来谈论抽象的概念,如时间。例如,我们经常会说:你“花费”或“节省”时间;你经常没有足够的时间来“花费”;有时你“花费”的时间是“值得的”,而且你已经合理地“使用”了时间;你可能认识一个在“借用的时间”里活着的人。
类似地,我们还会将诸如快乐和悲伤等情绪状态概念化为物理学中的方向的概念,如“上”和“下”。例如,我们会说:我可能会“情绪低落”并“陷入沮丧”;我的心情可能会“一落千丈”;我的朋友经常让我“提起精神”,或者让我“情绪高涨”。
更进一步说,我们通常使用物理学中温度的概念来对社会交往概念化,比如,“我受到了热烈的欢迎” “她冷冰冰地凝视着我” “他对我很冷淡”。这些说法是如此根深蒂固,以至于我们根本没有意识到自己在以隐喻的方式讲话。莱考夫和约翰逊提出的这些隐喻揭示了我们对概念进行理解的物理基础这一主张,支持了巴斯劳的人们通过构建源自我们核心知识的心智模型的模拟来进行理解的理论。
心理学家通过许多有趣的实验探讨了上述想法。一组研究人员指出:不管一个人感受到的是身体上的温暖还是社交上的“温暖”,激活的似乎都是大脑的相同区域。为了研究这种可能的心理影响,研究人员对一组志愿者进行了接下来的实验。每位被试者都由一名实验人员陪同经过一段较短的电梯行程前往心理学实验室。在电梯里,实验人员请被试者拿一杯热咖啡或者冰咖啡几秒钟,以方便实验人员记录被试者的名字,而被试者并不知道这实际上是实验的一部分。进入实验室之后,每位被试者需要阅读关于同一个虚构人物的一段简短描述,然后被要求评价该人物某些性格特征。结果表明:在电梯中拿过热咖啡的被试者对该人物的评价明显比拿冰咖啡的被试者的评价更让人感到温暖。
其他研究人员也发现了类似的结果。此外,物理和社交范畴的“温度”之间这一连接的反向似乎也成立。其他研究组的心理学家发现:“温暖”或“寒冷”的社交经历也会导致被试感受到物理层面的温暖或寒冷。
尽管这些实验及其解释在心理学领域仍然存在争议,但其结果可被理解为支持了巴斯劳、莱考夫和约翰逊的观点:我们通过核心物理知识来理解抽象概念。如果物理意义上的“温暖”概念在心理上被激活,例如,通过手持一杯热咖啡,这也会激活更抽象、隐喻层面上的“温暖”概念,就像评价一个人的性格的实验那样,并且反之亦然。
抛开意识来谈理解是困难的。当我开始写这本书的时候,我打算完全回避意识的问题,因为它从科学角度来讲是如此充满争议,但不知为何,我仍然对一些意识方面的猜测很感兴趣。如果我们对概念和情境的理解是通过构建心智模型进行模拟来实现的,那么,也许意识以及我们对自我的全部概念,都来自我们构建并模拟自己的心智模型的能力。我不仅能在心智上模拟打着电话过马路的情境,还能在心智上模拟自己的这种想法,并预测自己接下来可能会想什么,也就是说,我们有一个关于自己心智模型的模型。为模型建构模型,模拟我们的模拟——为什么不可以呢?就像对温暖的物理感知,能够激活对温暖的隐喻感知,并且反之亦然,我们拥有的与物理感觉相关的概念可能会激活关于自我的抽象概念,后者通过神经系统的反馈,产生一种对自我的物理感知,你也可以将这里的“自我”称为意识。这种循环因果关系类似于侯世达所说的意识的“怪圈”:“符号和物理层面相互作用,并颠倒了因果关系,符号似乎拥有了自由意志,并获得了推动粒子运动的自相矛盾的能力。”
构建和使用我们的心智模型
到目前为止,我从心理学角度描述了人类与生俱来的,或在生命早期获得的核心直觉知识,以及这些知识如何成为构建了我们的各种观念的心智模型的基础。构建和使用这些心智模型依赖于两种基本的人类本能:抽象和类比。
抽象是将特定的概念和情境识别为更一般的类别的能力。让我们把抽象这一概念描述得更加具体些。假设你是一位家长,同时又是一位认知心理学家,为方便表述,让我们把你的孩子称作“S”。在你观察S成长的过程中,你通过写日记来记录她日益增长的、复杂的抽象能力。下面,我来设想一下这些年来你可能会记下的一些内容。
3个月:S能够区分我表达快乐和悲伤的面部表情,并将其泛化到其他与之交流的不同的人身上。她已经抽象出了“一张快乐的脸庞”和“一张悲伤的脸庞”的概念。
6个月:S现在能够在人们向她挥手告别时识别出其含义了,并且她能够挥手回应。她抽象出了“挥手”的视觉概念,同时学会了如何使用相同的手势做出回应。
18个月:S已经抽象出了“猫”和“狗”,以及许多其他类别的概念,因此,她能够在图片、绘画和动画片,以及现实生活中识别各种不同种类的猫和狗了。
3岁:S可以从不同人的手写字迹和印刷字体中识别出字母表中的单个字母了。另外,她还能区分大小写字母,总之,她对与字母相关概念的抽象已经相当高级了!此外,她还将自己对胡萝卜、西兰花、菠菜等的知识归纳为更抽象的概念——蔬菜,而且现在她将蔬菜等同于另一个抽象概念——难吃的。
8岁:我无意中听到S最好的朋友J告诉S,有一次J的妈妈在她足球比赛后忘了去接她。S回应说:“嗯,在我身上也发生过完全相同的事情。我猜你一定很生气,而你妈妈觉得非常愧疚。”然而,这个“完全相同的事情”实际上是一个相当不同的情境:S的保姆忘记去学校接她,并忘记带她去上钢琴课。当S说“在我身上发生过完全相同的事情”时,很明显她已经构建了一个抽象的概念,类似于一个看护人忘记在某个活动之前或之后接送孩子的情境。她还能够将自己的经验映射到J和J的母亲身上,来预测她们肯定会有的反应。
13岁:S成长为一个叛逆的青少年。我反复要求她打扫她自己的房间。今天她对我喊道:“你不能逼迫我!亚伯拉罕·林肯解放了奴隶!”我很生气,主要原因在于她使用了不恰当的类比。
16岁:S对音乐的兴趣日渐浓厚。我们俩喜欢在车里玩一个游戏:我们打开一个古典音乐电台,看谁能更快地猜出某段音乐的作曲人或年代。在这方面仍然是我更擅长,但是S在识别某种音乐风格的抽象概念方面做得越来越好。
20岁:S给我发了一封关于她大学生活的长长的电子邮件。她把自己的一周描述为“一个学习‘松’,紧跟着一个吃饭‘松’和一个睡觉‘松’”(a study-a-thon, followed by an eat-a-thon and a sleep-a-thon)。她说,大学正在把她变成一个“咖啡瘾君子”(coffeholic)。S可能甚至都没意识到这点,但她的信息提供了在语言中常见的一种抽象形式的几个很好的案例:通过添加表示抽象情境的后缀来形成新单词。添加的“a-thon”源于“marathon”(马拉松),表示长度过长或数量过大的活动;添加的“holic”源于“alcoholic”(酒鬼),表示“沉迷于”。
26岁:S从法学院毕业,进入了一家知名的律师事务所。她最近的客户(被告)是一家提供公共博客平台服务的互联网公司,该公司被一名男子(原告)以诽谤罪起诉,因为该公司平台上的一名博主撰写了关于原告的诽谤性言论。S向陪审团提出的观点是:博客平台就像一堵各种人选择在上面“涂鸦”的“墙”,而这家公司只是这堵墙的所有者,因此不应对内容承担责任。陪审团认同她的观点,做出了有利于被告的审判。这是她在法庭上的第一次大胜!
我提及这一想象出来的家长日记的目的是,阐述一些关于抽象和类比的重要观点。从某种形式上来说,抽象是我们所有概念的基础,甚至从最早的婴儿时期就开始了。像是在不同的光照条件、角度、面部表情以及不同的发型等条件下识别出母亲的面庞,这样简单的事情,与识别一种音乐风格,或是做出一个有说服力的法律上的类比,是同样的抽象的壮举。正如上面的日记所表明的:我们所谓的感知、分类、识别、泛化和联想都涉及我们对所经历过的情境进行抽象的行为。
抽象与“做类比”(analogy making)密切相关。侯世达几十年来一直研究抽象和做类比,在一种非常一般的意义上将做类比定义为:对两件事之间共同本质的感知。这一共同的本质可以是一个命名的概念,如“笑脸”“挥手告别”“猫”“巴洛克风格的音乐”,我们将其称为类别;或在短时间创造的难以用语言进行表达的概念,如一个看护者忘记在活动之前或之后接送孩子,或一个并不对公共写作空间中用户创作的内容承担责任的所有者,我们将其称为类比。这些心理现象是同一枚硬币的两面。在某些情况下,诸如“同一枚硬币的两面”的想法是从一个类比起步,但最终以习语的形式融入我们的词汇中,这使得我们更像是将其当作一个类别来对待。
简而言之,类比在很多时候是我们无意识地做出来的,这种能力是我们抽象能力和概念形成的基础。正如侯世达和他的合著者、心理学家伊曼纽尔·桑德尔(Emmanuel Sander)在《表象与本质》中所阐述的:“没有概念就没有思想,没有类比就没有概念。”
在本章中,我从心理学领域近期的研究中概括了一些观点,这些研究主要是关于人类在面对其所遇到的情境时适当理解和行动所遵循的心理机制。我们拥有的核心知识,有些是与生俱来的,有些是在成长过程中学到的。我们的概念在大脑中被编码为可运行(即模拟)的心智模型,以预测在各种情境下可能发生的事情,或者给定任一我们能想到的变化之后可能会发生什么。我们大脑中的概念,从简单的词语到复杂的情境,都是通过抽象和类比习得的。
我当然不是说抽象和类比涵盖了人类理解的所有组成部分。事实上,很多人已经注意到“理解”和“意义”等术语只是我们用来当作占位符的定义不明的术语,更不用说意识了,因为目前我们还没有用来讨论大脑中究竟发生了什么的准确的语言或理论。人工智能的先驱马文·明斯基这样说道:“尽管近代科学出现了一些思想萌芽,使得‘believe’(相信)、‘know’(知道)、‘mean’(意味着)这样的词语在日常生活中变得很常用,但严格来说,它们的定义似乎太过粗糙,以至于无法支撑强有力的理论……就如同目前的‘self’(自我)或‘understand’(理解)这样的词语对我们而言一样,它们尚处于通往更完善的概念的起步阶段。”明斯基继续指出:“我们对这些概念的混淆,源于传统思想不足以解决这一极度困难的问题……我们现在还处在关于心智的一系列概念的形成期。”
直到最近,关于何种心智机制使得人们理解世界,以及机器是否也能拥有这样的机制的研究,几乎无一例外是所有哲学家、心理学家、神经科学家和具有理论头脑的人工智能研究人员所关注的领域。他们已经就这些问题进行了数十年,甚至数个世纪的学术辩论,但却很少关注其对现实世界的影响。正如我在前几章中所描述的那样,缺乏像人类那样的理解能力的人工智能系统现在正被广泛应用于现实世界中。突然之间,曾经一度仅仅是学术探讨的问题,开始在现实世界中变得愈发重要了。为了可靠、稳定地完成其工作,人工智能系统需要在多大程度上拥有像人类那样的理解能力?或达到多大程度上的近似?没有人知道答案,但人工智能领域的研究者都认同这样的观点:掌握核心常识以及复杂的抽象和类比能力,是人工智能未来发展不可或缺的重要一环。在下一章中,我将描述为机器赋予这些能力的一些方法。
赋予人工智能核心常识
自20世纪50年代以来,人工智能领域的研究探索了很多让人类思想的关键方面,如核心直觉知识、抽象与做类比等,融入机器智能的方法,以使得人工智能系统能够真正理解它们所遇到的情境。在本章中,我将描述在这些方向上取得的一些成果,其中也包括我自己在过去和现在的一些研究。
• 让计算机具备核心直觉知识
在人工智能发展的早期阶段,机器学习和神经网络还尚未在该领域占主导地位,那时候,人工智能研究人员还在人工地对程序执行任务所需的规则和知识编码,对他们来说,通过“内在建构”的方法来捕获足够的人类常识以在机器中实现人类水平的智能,看起来是完全合理的。
坚持为机器人工编写常识的最著名和持续时间最久的是道格拉斯·雷纳特(Douglas Lenat)的“Cyc”项目。雷纳特当时是斯坦福大学人工智能实验室的一名博士生,后来晋升为该实验室的教授,由于开发了模拟人类发明新概念(特别是在数学领域)的程序,他在20世纪70年代人工智能领域的研究群体中赢得了名声。经过对这一课题10多年的研究,雷纳特得出了一个结论:要想令人工智能实现真正进步,就需要让机器具备常识。因此,他决定创建一个庞大的关于世界的事实和逻辑规则的集合,并且使程序能够使用这些逻辑规则来推断出它们所需要的事实。1984年,雷纳特放弃了他的学术职位,创办了一家名为“Cycorp”的公司来实现这一目标。
“Cyc”这一名字意指唤醒世界的“百科全书”(encyclopedia),但与我们所熟知的百科全书不同,雷纳特的目标是让Cyc涵盖人类拥有的所有不成文的知识,或者至少涵盖足以使人工智能系统在视觉、语言、规划、推理和其他领域中达到人类水平的知识。
Cyc是我在第01章中描述过的那种符号人工智能系统—— 一个关于特定实体或一般概念的论断的集合,使用一种基于逻辑的计算机语言编写而成。以下是一些Cyc中的论断的例子:
• 一个实体不能同时身处多个地点。
• 一个对象每过一年会老一岁。
• 每个人都有一个女性人类母亲。
Cyc还包含很多用于在论断上执行逻辑推理的复杂算法。例如,Cyc可以判定如果我在波特兰,那么我就不在纽约,因为我是一个实体,波特兰和纽约都是地点,而一个实体不可能同时出现在多个地点。Cyc还有大量的方法来处理其集合中出现的不一致或不确定的论断。
Cyc的论断由Cycorp的员工手动编码,或由系统从现有的论断出发,通过逻辑推理编码到集合中。那么究竟需要多少论断才能获得人类的常识呢?在2015年的一次讲座中,雷纳特称目前Cyc中的论断数量为1500万,并猜测说:“我们目前大概拥有了最终所需的论断数量的5%左右。”
Cyc背后的基本理念与人工智能领域早期的专家系统有很多共同之处。你可能还记得我在第02章中对MYCIN医学诊断专家系统的讨论。MYCIN的开发人员会通过对医学专家(医生)的访谈,来获知系统用于诊断的规则。然后,开发人员会将这些规则转换为基于逻辑的计算机语言,使得系统可执行逻辑推理。在Cyc中,专家是指人工将他们关于世界的知识转化为逻辑语句的人。Cyc的知识库比MYCIN的要大得多,Cyc的逻辑推理算法也更复杂,但这些项目有相同的核心理念:智能可通过在一个足够广泛的显性知识集合上运行人类编码的规则来获取。在当今由深度学习主导的人工智能领域内,Cyc是仅存的大规模符号人工智能的成果之一。
有没有这样一种可能:只要付出足够多的时间和努力,Cycorp的工程师就真的能成功地获取全部或足够多的人类常识,不管这个“足够多”具体是多少?我对此保持怀疑。比如,很多处于我们潜意识里的知识,我们甚至不知道自己拥有这些知识,或者说常识,但是它们是我们人类所共有的,而且是在任何地方都没有记载的知识。这包括我们在物理学、生物学和心理学上的许多核心直觉知识,这些知识是所有我们关于世界的更广泛的知识的基础。如果你没有有意识地认识到自己知道什么,你就不能成为向一台计算机明确地提供这些知识的专家。
此外,正如我在前一章中所指出的:我们的常识是由抽象和类比支配的,如果没有这些能力,我们所谓的常识就不可能存在。我认为:Cyc无法通过其大量事实组成的集合和一般逻辑推理来获得与人类拥有的抽象和类比能力相类似的技能。
在我撰写本书时,Cyc已经走进了它的第四个十年。Cycorp及其子公司Lucid都在通过为企业提供一系列定制化的应用来实现Cyc的商业化,公司的网站有众多成功案例:Cyc在金融、油气开采、医药和其他特定领域的应用。在某些方面,Cyc的发展轨迹与IBM的沃森很相似:也是以充满远大前景和雄心壮志的基础人工智能研究为开端,辅以一系列夸张的营销声明,例如,宣称Cyc给计算机带来了类似于人类的理解和推理的能力,但其关注的领域却是狭隘的而非通用的,并且关于系统的实际表现和能力也很少向公众透露。
到目前为止,Cyc还没有对人工智能的主流研究产生太大的影响。此外,一些人工智能研究人员尖锐地批评了这一项目。例如,华盛顿大学的人工智能教授佩德罗·多明戈斯(Pedro Domingos)评价Cyc是“人工智能历史上最臭名昭著的失败案例”;麻省理工学院的机器人专家罗德尼·布鲁克斯稍微友善那么一点点,他说:“尽管Cyc是一次英勇的尝试,但它并未使得人工智能系统能够掌握对世界哪怕是一丁点儿简单的理解。”
如果把那些我们在婴幼儿时期就学到的,构成了我们所有概念之基础的关于世界的潜意识知识,都输入计算机,那会怎么样?例如,我们是否可以教一台计算机关于物体的直觉物理学?多个研究团队已接受这一挑战,并正在构建能学习一些关于世界因果物理关系的知识的人工智能系统。他们的方法是从视频、电子游戏或其他类型的虚拟现实中进行学习。这些方法虽然很有趣,但目前为止只是朝着开发直觉核心知识方面迈出了一小步——与真实的婴儿所知道的相比。
当深度学习开始展示其一系列非凡的成功时,不管是人工智能领域的内行还是外行,大家都乐观地认为我们即将实现通用的、人类水平的人工智能了。然而,正如我在本书中反复强调的那样,随着深度学习系统的应用愈加广泛,其智能正逐渐露出“破绽”。即便是最成功的系统,也无法在其狭窄的专业领域之外进行良好的泛化、形成抽象概念或者学会因果关系。此外,它们经常会犯一些不像人类会犯的错误,以及在对抗样本上表现出的脆弱性都表明:它们并不真正理解我们教给它们的概念。关于是否可以用更多的数据或更深的网络来弥补这些差距,还是说有某些更基本的东西被遗失了,人们尚未达成一致意见。
我在最近发生的一些事中看到了这样一种转变:人工智能领域再一次越来越多地讨论关于赋予机器常识的重要性。2018年,微软联合创始人保罗·艾伦将其创立的艾伦人工智能研究所的研发预算增加了一倍,专门用于研究常识。政府资助机构也正对此采取行动,美国最主要的人工智能研究资助机构之一 ——美国国防部高级研究计划局公布了为人工智能常识研究提供大量资助的计划,计划中写道:“当前的机器推理仍然是狭隘且高度专业化的,大范围、常识性的机器推理仍然是难以达到的。这项资助计划将创建更类似人类的知识表征,例如,基于感知的表征,从而使得机器能够对物理世界和时空现象进行常识性推理。”
• 形成抽象,理想化的愿景
“建构抽象”是我在第01章中描述过的1956年达特茅斯人工智能计划中列出的人工智能的关键能力之一。然而,使机器形成类似于人类的概念化抽象能力仍然是一个悬而未决的问题。
抽象和类比正是最初吸引我进入人工智能研究领域的课题。当我遇到一组名为邦加德问题(Bongard problems)的视觉谜题时,我的兴趣突然被点燃了。这些谜题是由俄罗斯计算机科学家米哈伊尔·邦加德(Mikhail Bongard)设置的,他在1967年出版了一本名为《模式识别》(Pattern Recognition)的俄文书。这本书描述的是邦加德关于一个类似感知器的视觉识别系统的提案,但该书中最具影响力的部分却是它的附录,其中邦加德为人工智能程序提供了100个谜题作为挑战。图2给出了选自邦加德题集的4个问题。 每个问题由12个方框组成:左右两侧各6个。每个问题左侧的6个方框举例说明其具有相同的某一个概念;右侧的6个方框举例说明了与之相关的另一个概念,这两个概念可以完美地区分这两个集合,问题的关键在于找到这两个概念。例如,在图2中表示的概念按顺时针顺序分别是:大与小;白色的与黑色的(或未填充与填充);靠右侧与靠左侧;垂直与水平。
图2中的问题相对容易解决。实际上,邦加德大致按照预测的难度对这100个问题进行了排序。为了增添一些乐趣,图3是从题集后面节选的6个额外的问题,我将在下面的叙述中给出答案。
邦加德精心设计了这些谜题,使得它们的解决方案要求人工智能系统具备与人类在现实世界中所需的同样的抽象和类比能力。在一个邦加德问题中,你可以将12个方框中的每一个视为一个微型的、理想化的情境:一个展示了不同的对象、属性及其关系的情境。左侧6个方框表示的情境具有一个共性(例如,大);右侧6个方框表示的情境具有一个与之相对的共性(例如,小)。并且在邦加德问题中,识别一种情境的本质有时是很微妙的,正如在现实生活中一样。就如心理学家罗伯特·弗伦奇(Robert French)所说的,抽象和类比都在于感知共性的微妙之处。
为发现这种微妙的共性,你需要确定情境中的哪些属性是相关的,而哪些可以忽略掉。在问题2中(见图3),一个图形是黑色还是白色,或者位于框中的什么位置,以及其形状是三角形、圆形还是其他,这些都无关紧要,图形的大小是此处唯一重要的属性。当然,大小也并不总是重要的,比如,在图2中的其他问题里,大小这种属性就是无关的。我们人类是如何快速地识别相关属性的呢?我们怎么才能让机器做同样的事情?
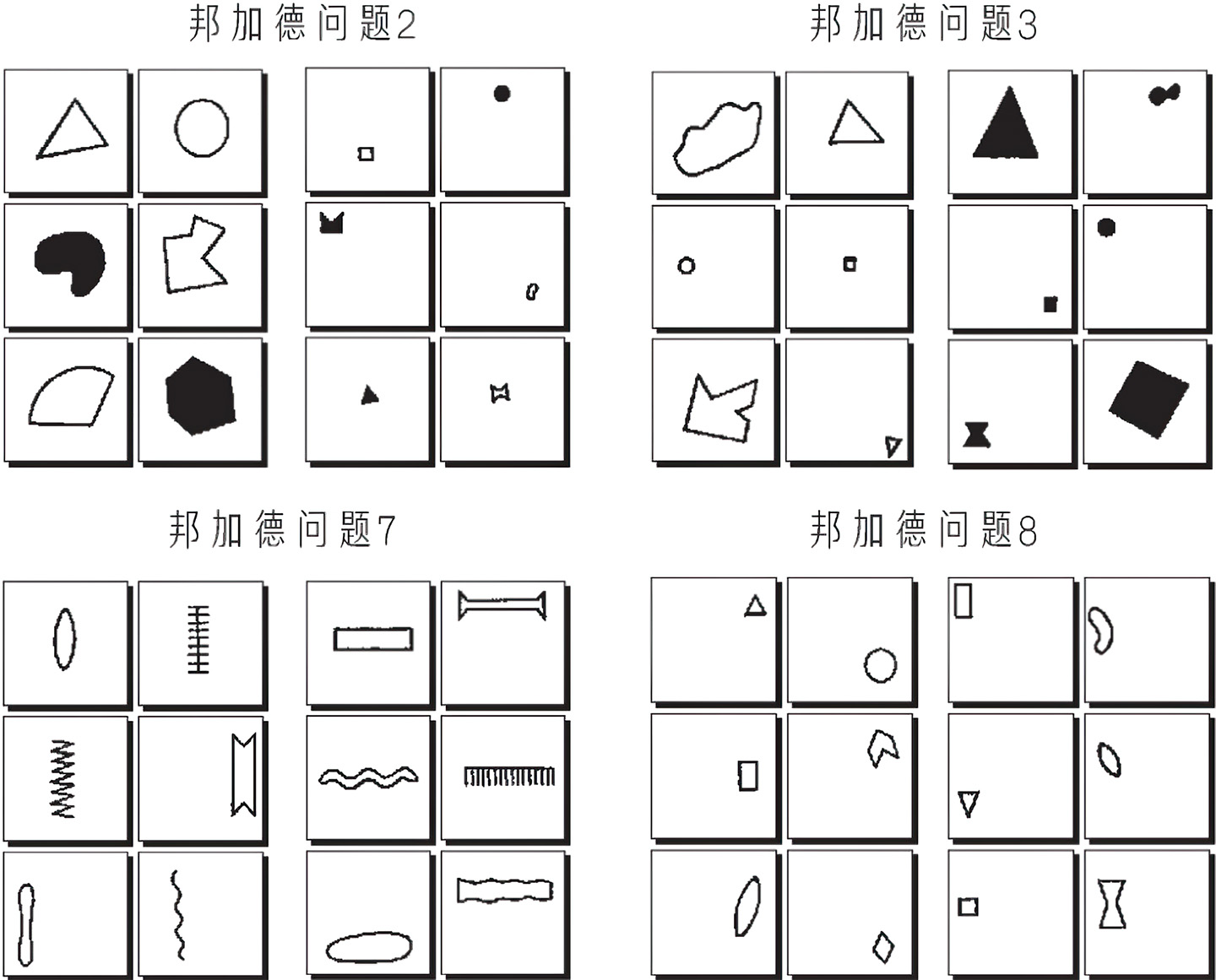
注:对于每个问题,其任务是判定哪些概念可以用来区分左侧的6个框与右侧的6个框中的内容。
例如,对邦加德问题2,其对应概念是“大”与“小”。

为了给机器一些更难的挑战,相关的概念可以用一种抽象的、难以感知的方式来编码,如问题91(见图3)中的概念“3”和“4”。在某些问题中,一个人工智能系统要弄清楚什么才能算作一个概念可能并不容易,像在问题84(见图3,“在外面”与“在里面”)中其相关对象由更小的对象(圆圈)组成,而在问题98(见图3)中,对象甚至被伪装了:人类很容易看出来这些是什么图案,但对机器而言却很难,因为机器很难区分前景和背景。
邦加德问题也挑战了人类迅速感知新概念的能力,问题(见图3)是一个很好的例子。在这个问题中,左侧方框中的通识概念很难用语言表达,它就像是具有一个收缩的或类似于人类颈部的对象,但即便你在此之前从未想到过任何与之类似的对象,你也能在问题18中快速识别出来。类似地,在问题19(见图3)中,有一个新概念:左边是一个类似水平颈部的对象,而右边是一个具有垂直颈部的对象。抽象化新的、难以描述的概念真的是人类非常擅长的事情,但目前所有的人工智能系统都无法以任何通用的方式做到这点。
邦加德的书,在1970年出版过英文版本,非常晦涩难懂,并且最初只有很少的人知晓其存在。侯世达于1975年偶然发现了这本书,并且对附录中的100个邦加德问题印象深刻,后来,他在自己的著作“GEB”中用了很长的篇幅讲述了这些问题,我也是从“GEB”中第一次看到它们。
从小时候起,我就一直很喜欢谜题,尤其是涉及逻辑或模型的。当我阅读“GEB”时,我对邦加德问题尤其着迷。我对侯世达在“GEB”中描述的关于如何以模拟人类感知和做类比的方式来创建一个能解决邦加德问题的程序也很感兴趣。很可能是从阅读到那部分内容的那一刻起,我决定成为一名人工智能领域的研究人员。
许多人也同样被邦加德问题迷住了,一些研究人员已经创建了用来解决这些问题的人工智能程序,其中大多数都简化了假设,例如,限制可被允许出现的图形形状和形状关系集合,或者完全忽略了视觉方面而仅从一个人工创建的图像描述开始。每一个程序都能够解决特定问题的一个子集,但还没有人表示它们的方法可以像人类那样进行泛化。
鉴于ConvNets在对象分类上的表现如此出色(你可以回想下我在第05章中描述的盛大的ImageNet“视觉识别挑战赛”上ConvNets的表现),那么,我们是否可以通过训练这样一个网络来解决邦加德问题呢?你可以假设将一个邦加德问题建构为ConvNets的一种分类问题,如图4中所示:左侧的6个方框可以被视为类别1中的训练样本,而右侧的6个方框是类别2中的训练样本。现在给系统一个新的测试样本,它应该被归为类别1还是类别2呢?
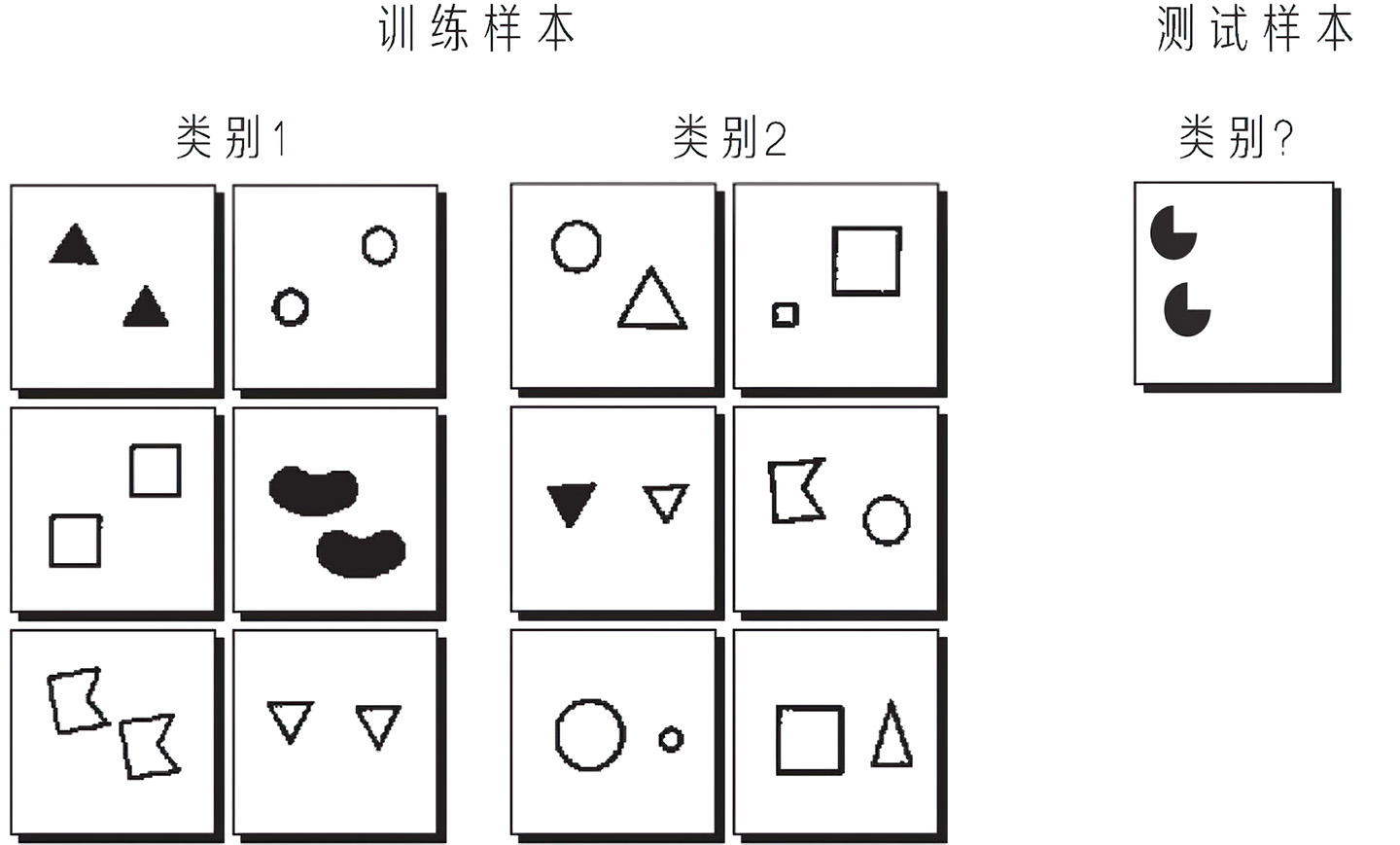
一个明显的障碍是:一组只有12个训练样本,这个样本量对训练一个ConvNet来说远远不够,即便是1200个可能也不够。邦加德的疑问是:我们人类只用12个样本就能轻松识别相关概念,一个ConvNets需要多少训练数据才能学会解决一个邦加德问题呢?尽管还没有人系统地研究过如何使用ConvNets来解决邦加德问题,但一组研究人员使用类似图4中的图像,测试了最新的ConvNets在“相同vs不同”任务上的表现。测试中,并非使用这12个训练图像,而是分别使用20000个类别1(方框中的图形相同)和类别2(方框中的图形不同)的样本对ConvNets进行训练。训练后,再让每个ConvNets在10000个新样本上进行测试,这些新样本都是自动生成的。训练过的ConvNets在这些“相同vs不同”任务上的表现仅略好于随机猜测,相比之下,由研究人员测试的人类的准确率接近100%。
简而言之,尽管目前的ConvNets非常善于学习识别ImageNet中对象的特征,或选择围棋中下一步的走法,但是,它甚至连理想化的邦加德问题中所需要的抽象和类比的能力都尚不具备,更不用说对现实世界中的对象进行抽象和类比了。看来,ConvNets学到的这些种类的特征,还不足以构建这种抽象能力,就算使用再多训练样本也一样。不单是ConvNet不行,任何现有的人工智能系统都不具备人类的这些基本能力。
• 活跃的符号和做类比
在读完“GEB”并决定从事人工智能领域的研究之后,我找到了侯世达,希望能从事一些类似于解决邦加德问题的研究工作。令人开心的是:我最终说服了他,并加入了他的研究团队。侯世达向我解释道,他的团队实际上正在构建一种计算机程序,灵感来自人类如何理解和类比不同情境。当他完成了物理学领域的研究工作后,侯世达坚信,研究一种现象的最好方式就是研究它最理想化的形式,这对于研究人类是如何做类比的同样适用。人工智能研究中通常使用所谓的“微观世界”(就是一种理想化的情境,比如邦加德问题),研究人员能够在其中先开发一些想法,再在更复杂的领域中进行测试。为了研究类比,侯世达甚至构建了一个比邦加德问题更加理想化的微观世界:关于字符串的类比问题。如下是一个例子:
问题1:假设字符串abc改动为abd,你如何以相同的方式改动字符串pqrs?
大多数人的答案是pqrt,他们推断出这样一条规则:“将最右边的字母替换为它在字母表中的后一个字母。”当然,我们还有可能会推断出一些其他规则,从而产生不同的答案。这里有几个可替代的答案:
pqrd:用d替换最右边的字母。
pqrs:用d替换所有c,pqrs中没有c,所以不做任何变动。
abd:用字符串abd替换任何字符串。
这些可替代答案可能看起来会太过字面化,但没有任何严格的逻辑论证可以证明它们是错误的。事实上,我们可以推断出无限多的可能规则,但为什么大多数人都认同其中的pqrt这个答案是最好的?似乎我们为促进自身在现实世界中的生存和繁衍而演化出的关于抽象的心理机制,延续到了这个理想化的微观世界中。
这里还有另外一个例子:
问题2:假设字符串abc改动为abd,你将如何以相同的方式改动字符串ppqqrrss?
即便是在这个简单的字母构成的微观世界中,其可能存在的共性也是相当微妙的,至少对一台机器来说是如此。在问题2中,如果生硬地应用规则“将最右边的字母替换为它的后一个字母”,你得到的答案将会是:ppqqrrst,但对大多数人来说这个答案看起来太刻板了,人们倾向于给出“ppqqrrtt”这个答案,这是基于对ppqqrrss中的字符对的感知,并将其映射到abc中的每一个字符。18我们人类总是倾向于把一模一样的或相似的对象归为一组!
问题2阐明了:在这个微观世界中,概念滑移(conceptual slippage)这一概念是做类比的核心。当你试图感知两种不同情境在本质上的共性时,来自第一种情境的某些概念需要“滑移”到第二种情境中,即被第二种情境中的相关概念所取代。在问题2中,字母通过概念滑移变为字母组,因此,“将最右边的字母替换为它的后一个字母”这一规则也应变为“将最右边的字母组替换为它的后一个字母组”。
现在考虑这个问题:
问题3:假设字符串abc改动为abd,你将如何以相同的方式改动字符串xyz?
大多数人回答“xya”,他们认为z的后一个字母是a,但是对于一个没有循环字母表概念的计算机程序来说,字母z没有后一个字母。那么,还有什么其他答案是合理的吗?当我请大家来回答这个问题时,我得到了很多不同的回复,其中一些很有创意。有趣的是,这些答案往往触发了物理上的隐喻。例如,xy(z从悬崖边上坠落了)、xyy(z弹回来了)和wyz。对于最后一个答案,我们可以这样理解:a和z作为字母表的两端各自被钉在墙上,所以它们作用相似,因此,如果字母表中的第一个字母(a)的概念滑移到了字母表的最后一个字母(z)上,那么最右边的字母(z)的概念则应该滑移到最左边的字母(a)上,而第二个字母(b)的概念则滑移到倒数第二个字母(y)上,以此类推。问题3阐明了做类比如何能引发一连串的概念滑移。
在由字符串构成的微观世界中,概念滑移是非常直观的。在其他领域,它会更加微妙。例如,回顾一下图15-2中的邦加德问题91,其中左侧6个框的共同本质是“3”,表示“3”这一对象的概念从一个框向另一个框滑移,例如,从线段(左上)到正方形(左中),然后再到左下框中表示的难以用文字描述的概念(可能是类似于梳子上的齿的东西)。概念滑移也是前一章中假想出来的女儿S多年来所做的不同抽象的核心特征,例如,在关于法律的那个类比中,她把网站的概念滑移至墙的概念,以及把写博客的概念滑移至涂鸦的概念。
侯世达设想了一个名为“Copycat”的计算机程序,它可以通过使用非常通用的算法来解决这类问题,这种算法类似于人类在任何领域做类比时都会使用的算法。Copycat这个名字源于这样一种想法:做类比的人可以通过做同样的事情,即通过成为一个模仿者来解决这些问题。原始的情境(如abc)在某种程度上发生了改动,而你的任务就是对新情境(如ppqqrrss)做相同的改动。
当我加入侯世达的研究团队时,我的任务是和他一起开发Copycat程序。任何一个经过这段历程的人都会这样告诉你:通往博士学位的道路充斥着各种令人沮丧的挫折和高强度的劳动,以及时常会出现的强烈的自我怀疑,但偶尔也会出现令人振奋的成功时刻,比如,你坚持研究了5年的程序终于运作起来了。在这里我将跳过所有我经历过的怀疑、挫折和大量的工作时间,直接跳到最后的结果:当我提交了一篇论述Copycat程序的学位论文时,我认为这个程序已经能够以通用的、与人类相似的方式解决多种字符串类比的问题了。
Copycat既不是一个符号化的、基于规则的程序,也不是一个神经网络,尽管它同时包含了符号人工智能和亚符号人工智能的一些特性。Copycat通过程序的感知过程(即观察一个特定的字符串类比问题的特征)及如字母和字母组、后者和前者、相同和相反等先验概念之间的持续交互来解决类比问题。这个程序被构造成一种可以模仿我在前一章中描述的心智模型的东西,特别是,它们都基于侯世达关于人类认知中活跃符号(active symbols)的概念。Copycat的架构很复杂,我就不在这里进一步描述了,如果想了解更多内容,请参考书后的相关注释。虽然Copycat可以解决许多字符串类比问题,比如我在上面展示的例子,以及许多变体问题,但该程序只触及了这一开放领域的皮毛。例如,下面是这个程序无法解决的两个问题:
问题4:如果azbzczd改动为abcd,那么pxqxrxsxt将会改动为什么?
问题5:如果abc改动为abd,那么ace将会改动为什么?
这两个问题都需要凭空识别新概念,这是Copycat所欠缺的一种能力。在问题4中,z和x扮演的角色相同,即为看出字母序列而需要被删除的额外字母,从而得出其答案为pqrst。在问题5中,ace序列类似于abc序列,但是它不是一个“后继”序列,而是一个“双重后继”序列,从而得出其答案为acg。对我来说,很容易就能给予Copycat计算a和c之间、c和e之间的字母数量的能力,但是我不想构建那些非常具体的针对特定字符串域的功能。Copycat是用来测试与类比相关的一般观念的平台,而非一个全面的“字符串类比制造机”。
• 字符串世界中的元认知
人类智能的一个必不可少的方面,是感知并反思自己的思维能力,这也是人工智能领域近来很少讨论的一点,在心理学中,这被称作“元认知”。你是否曾经苦苦挣扎着想要解决一个问题但并未成功,最后却发现自己一直在重复同样的无效思维过程?这种情况经常发生在我身上,然而,一旦我认识到自己处于这种模式,我有时就能打破常规。Copycat与我在本书中讨论的其他所有人工智能程序一样,没有自我感知的机制,而这会影响它的性能表现。该程序有时会陷入一种困境:一次又一次地尝试使用错误的方式解决问题,并且永远无法意识到它之前已经走过了一条类似的无法通往成功的道路。
詹姆斯·马歇尔(James Marshall)当时是侯世达研究团队的一名研究生,承担了一个让Copycat“反思”自己的思维过程的项目。他创建了一个名为“Metacat”的程序,Metacat不仅解决了Copycat字符串领域中的类比问题,还试图让Copycat感知其自身的行为。当程序运行时,它会对自己在解决问题的过程中识别到的概念生成一条运行注解。和Copycat一样,Metacat虽然展示了一些令人欣喜的行为,但也仅触及了人类自我反思能力的表象。
• 识别整个情境比识别单个物体要困难得多
我目前的研究方向是研发一个使用类比来灵活地识别“视觉情境”(visual situations)的人工智能系统,视觉情境是一种涉及多个实体及其之间关系的视觉概念。例如,图5中的4幅图像,我们都可称之为“遛狗”这一视觉情境的实例。人类很容易就能看出来,但是对于人工智能系统来说,即便是识别简单视觉情境中的实例,也非常具有挑战性,识别整个情境比识别单个物体要困难得多。
我和我的同事正在开发一个名为“Situate”的程序,它将DNN的目标识别能力与Copycat的活跃符号结构相结合,通过做类比来识别某些特定情境。我们希望它不仅能够识别如图5中的简单明了的情境,而且能够识别需要进行概念滑移的非常规的情境。我们从图5的示例中可以看到:“遛狗”情境的原型包括一个人、一条狗和一条狗绳,遛狗者牵着狗绳,狗绳系在狗身上,并且遛狗者和狗都在行走。理解“遛狗”这一概念的人也会将图6中的每幅图像看作是这个概念的示例,并且还能意识到每幅图像从原型版本上“拓展”了多少。Situate目前仍处于研发的早期阶段,其目的是探究隐藏在人类类比能力背后的一般机制,并证明隐藏在Copycat程序背后的机制也可以在字符串类比这个微观世界之外成功地运行。
Copycat、Metacat和Situate仅仅是基于侯世达的活跃符号结构构建的类比程序中的3个示例。此外,活跃符号结构只是人工智能领域中创建的能够做类比的程序的众多方法之一。尽管类比对人类认知的任何层次来说都是基础性的,但目前为止还没有人工智能程序能具有人类的类比能力―—哪怕一点点。


• “我们真的,真的相距甚远”
现代人工智能以深度学习为主导,以DNN、大数据和超高速计算机为三驾马车,然而,在追求稳健和通用的智能的过程中,深度学习可能会碰壁——重中之重的“意义的障碍”。在本章中,我展示了人工智能为打破这一障碍所做的一些努力,我们可以看到研究人员(包括我自己)是如何为计算机灌输常识,并尝试赋予它们类似于人类的抽象和类比能力的。
在构思这一话题时,我被安德烈·卡帕西撰写的一篇令人愉快且见解深刻的博客文章迷住了,卡帕西是一名深度学习和计算机视觉领域的专家,他目前在指导特斯拉的人工智能的相关工作。卡帕西在其发表的一篇题为《计算机视觉和人工智能的现状:我们真的,真的相距甚远》的文章中,描述了自己作为一名计算机视觉研究人员对一张特定照片的反应(见图7)。卡帕西指出,我们人类会发现这张照片非常幽默,那么,问题来了:“一台计算机需要具备什么样的知识才能像你我一样去理解这张照片?”

卡帕西列出了许多我们人类轻易就能理解但仍然超出了当今最好的计算机视觉程序的能力范围的事物。例如,我们能够识别出场景中有人,也有镜子,因此有些“人”只是镜子中的影像;我们能够识别出图中的场景是一间更衣室,并且我们会对在更衣室里看到这样一群西装革履的人而感到奇怪。
再进一步,我们可以识别出一个人正站在体重秤上,尽管体重秤是由混合在背景中的白色像素组成的。卡帕西指出,我们可以发现奥巴马把他的脚轻轻地压在体重秤上,并强调,我们很容易根据我们推断出来的三维场景结构而不是这张二维图像来得出这一结论。我们对物理学的直觉知识使我们可以推断:奥巴马的脚踩着体重秤将导致体重秤上显示的数字大于体重秤上男士的真实体重。我们在心理学方面的直觉知识告诉我们:站在体重秤上的这个人并没有意识到奥巴马的脚踩在秤上,这能从那个人视线的方向推断出来,并且我们知道他的脑袋后面并没有长眼睛。我们还能明白:测量体重的人大概感觉不到奥巴马的脚正轻踏在秤面上。我们还能根据心智理论进一步推测:当体重秤显示的体重比他的预期要高时,他将很不开心。
最后,我们看得出奥巴马和其他观察这一场景的人都在微笑,他们被奥巴马对这个人开的这个玩笑逗乐了,并且可能因为奥巴马的身份让它变得更有趣了。我们也识别出他们的玩笑是友善的,并且他们期望站在秤上的人知道自己被捉弄之后也会开怀大笑。
卡帕西指出,“你在推理人们的心智状态,以及他们对其他人的心智状态的看法。这会变得越来越可怕……令人难以置信的是:上面所有的推论都是从人们对这幅二维的由像素构成的图像的简单一瞥而展开的”。
对我而言,卡帕西的例子完美地捕捉到了人类理解能力的复杂性,并以水晶般的清晰度展现了人工智能所面临的挑战之大。卡帕西的文章写于2012年,但其传递的信息在今天看来依然正确,我相信,在未来很长一段时间内都是这样。
卡帕西用下面这段文字概括了他的文章:
我几乎可以肯定的是:我们可能需要进一步探索“具身”(embodiment)这一概念。构建像我们这样能够理解各种场景的计算机的唯一方法,就是让它们接触到我们在这么多年来所拥有的结构化的和暂时的经验、与世界互动的能力,以及一些在我思考它应具备何种能力时几乎都无法想象的神奇的主动学习和推理的能力。
在17世纪,哲学家勒内·笛卡儿推测,我们的身体和思想是由不同的物质组成的,并受制于不同的物理定律。自20世纪50年代以来,人工智能的主流方法都隐晦地接受了笛卡儿的这一论点,假设通用人工智能可以通过非实体的程序来实现。但是,有一小部分人工智能研究群体一直主张所谓的具身假说:如果一台机器没有与世界进行交互的实体,那它就无法获得人类水平的智能。这种观点认为:一台放置在桌子上的计算机,甚至是生长在缸中的非实体的大脑,都永远无法获得实现通用智能所需的对概念的理解能力。只有那种既是物化的又在世界中很活跃的机器,才能在其领域中达到人类水平的智能。同卡帕西一样,我几乎无法想象若要制造这样一台机器,我们将需要取得哪些突破。历经多年与人工智能的“拼杀”之后,我发现关于具身的相关争论正越来越受到关注。![]()
本文经授权节选自《AI 3.0》
作者:[美] 梅拉妮·米歇尔
出版社:四川科学技术出版社·湛庐
出品方:湛庐文化
原作名:Artificial Intelligence: A Guide for Thinking Humans
译者:王飞跃 / 李玉珂 / 王晓 / 张慧
出版年:2021-2