



王鹏 腾讯研究院资深专家
经过漫长的等待,OpenAI终于在9月12日发布了新模型O1,用户可以直接访问预览版o1-preview,或者小尺寸版o1-mini。其酝酿了快一年的大招,一会儿Q*、一会儿草莓、一会儿AGI、一会儿GPT5,耗得核心技术团队都快走光了,才终于拿出来让所有人检验和评论。这样一个备受瞩目的产品,势必对行业甚至社会产生深远的影响。而且它不像平时那些版本更新一样,只是简单的技术能力提升,而需要从多个视角和维度去观察和预测其影响。
一、大进步
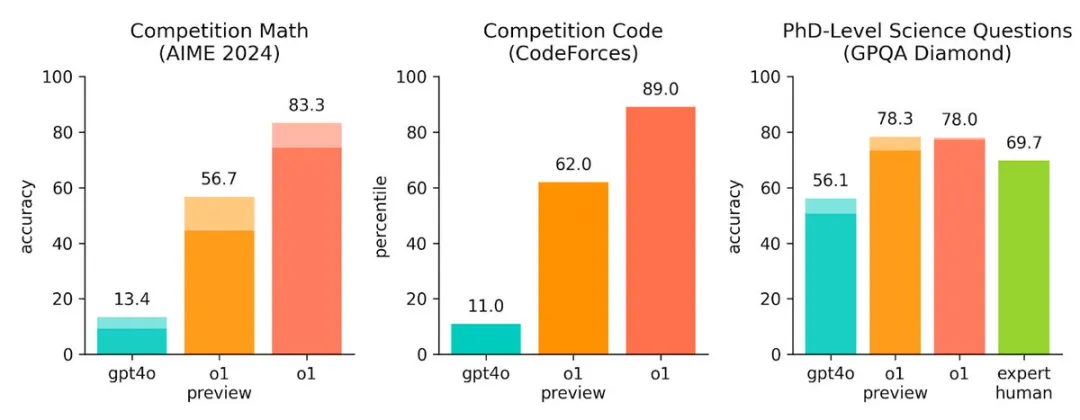
与GPT-4o相比,o1-preview在解决数学和编程问题上的能力提升了5倍以上,而还未放出的o1则超过8倍!在解决博士级别科学题目的时的成功率,都已经超过了人类专家的水平。理化竞赛能力都超过了人类博士的水平;在国际数学奥林匹克(IMO)资格考试中,GPT-4o 只正确解决了 13% 的问题,而推理模型的得分为 83%;编程能力在Codeforces 竞赛中超过了 89%的人类选手 。o1看起来在包括科学在内的各个领域都超过人类的最强能力,不难理解奥特曼之前对实现AGI的满满自信。
在实际操作中,可以看出新模型的推理过程与之前有很大区别。我们可以看到多了一个可以打开和关闭的Show chain of thought(显示思路)框,显示了整个思维过程。类似于人类在回答难题之前的长时间思考,o1 在尝试解决问题时会通过思考将问题分解,并步步为营,反复思考每个小任务,认识并纠正错误。当一个方法不起作用时,它会尝试另一种方法,从而极大提高了模型的推理能力。
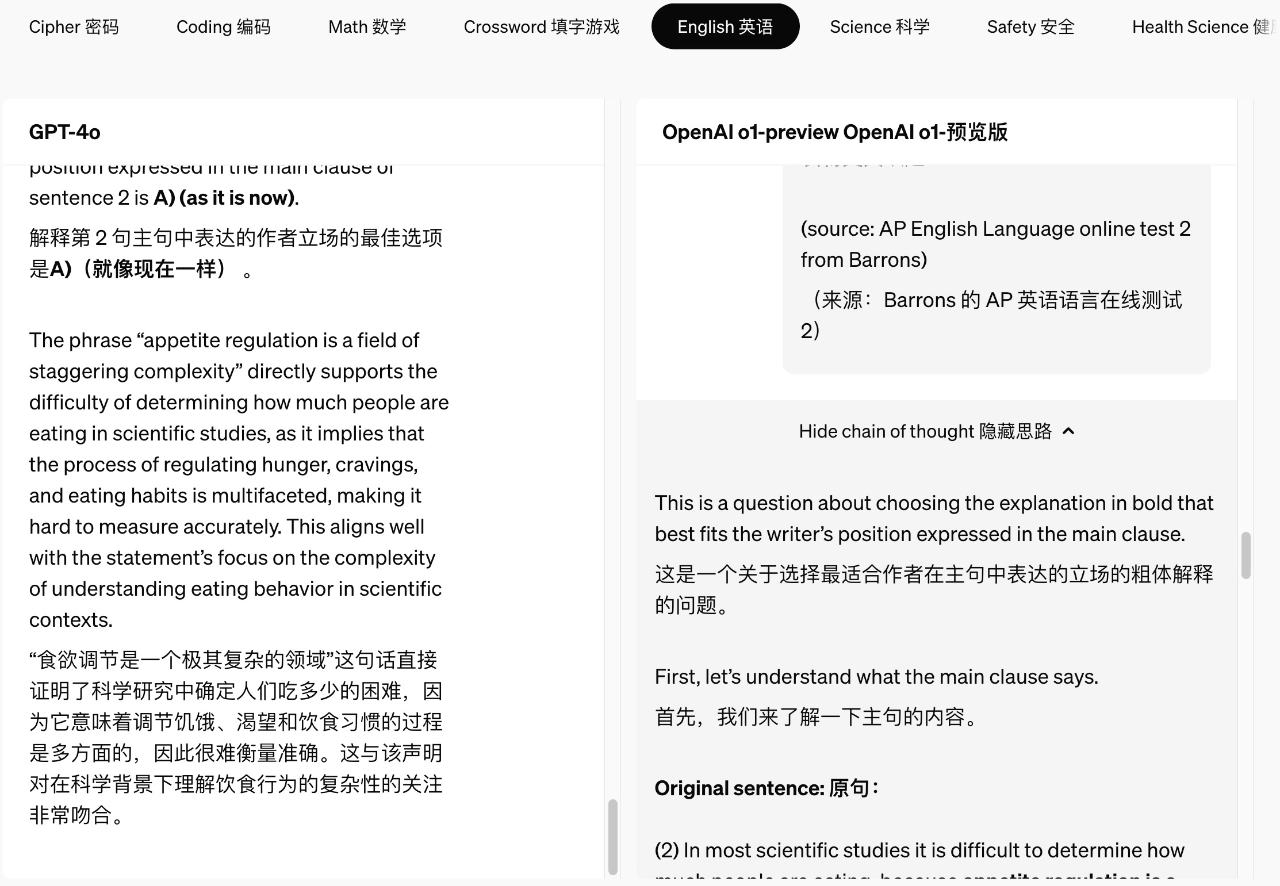
在这些激动人心的能力进展背后,一系列被大家长期猜测的技术进展也一一被验证。
1、思维链
CoT(Chain of thought,思维链),是学者们发现的能够激发大模型通过“思考”来回答困难问题的技术,可以显著提高其在推理等任务上的正确率。这个思路在两年前的几篇经典论文中已经得到不断完善。
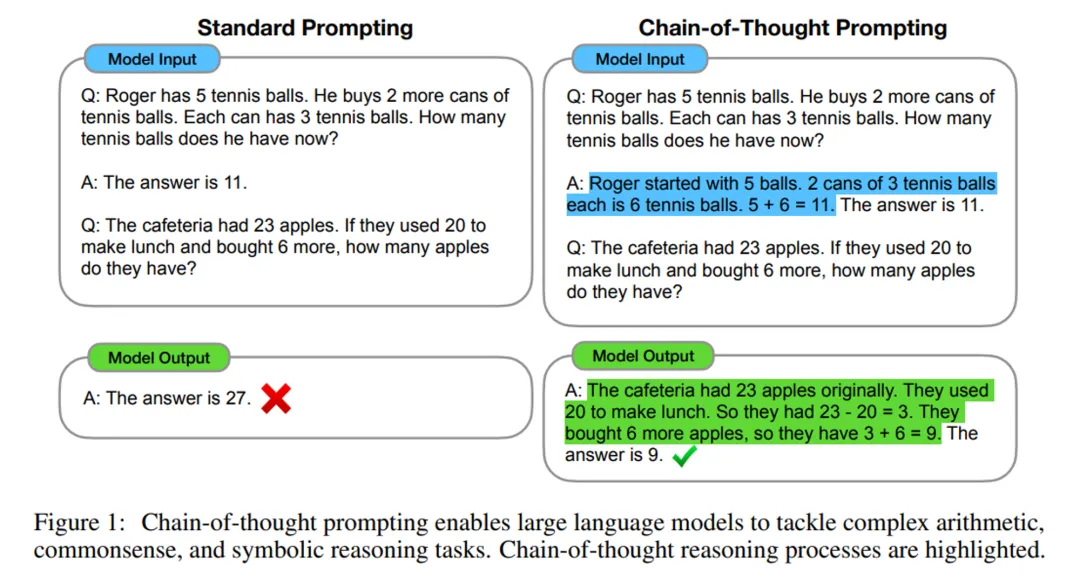
《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,NeurIPS2022》这篇文章提出,在问LLM问题前,手工在prompt里面加入一些包含思维过程(Chain of thought)的问答示例(Manual CoT),就可以让LLM在推理任务上大幅提升。
《Large language models are zero-shot reasoners. NeurIPS2022》提出先使用 “Let’s think step by step.” 让模型自己给出推理过程(Zero-shot CoT ),也衍生出诸如“一步一步慢慢来“这些著名的咒语。

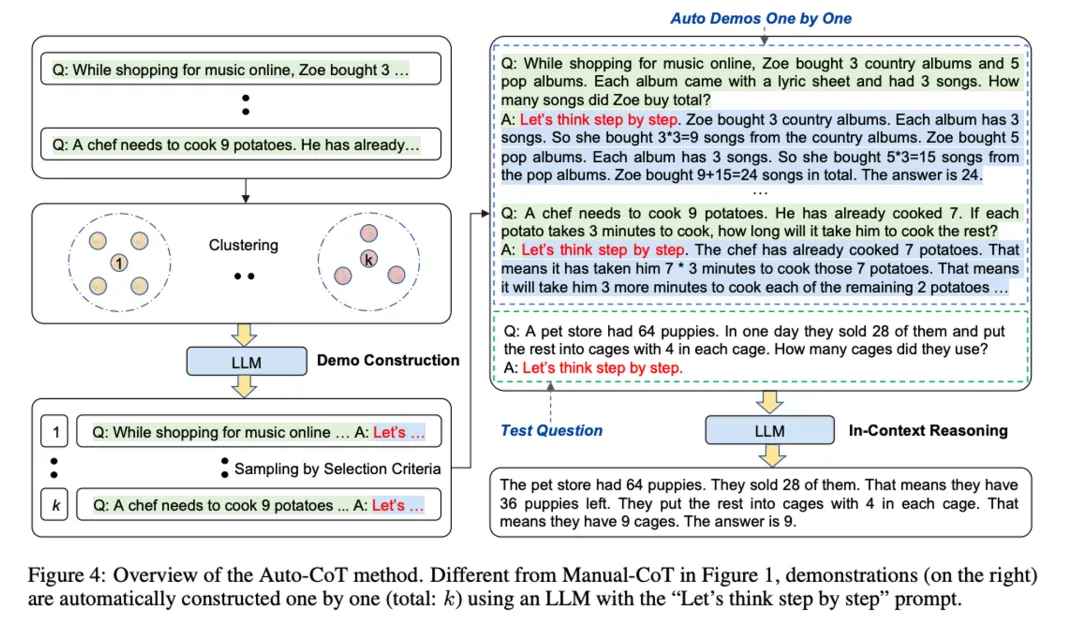
《Automatic Chain of Thought Prompting in Large Language Models,ICLR2023》这篇文章可以理解为二者的结合,先用 “Let’s think step by step.” 咒语产生推理过程,再把这些过程加到prompt里面去引导大模型推理。这样不需要自己写,又能相对靠谱。
在这些之后,CoT还经历了千变万化的演进,但大都还是通过prompt来诱导大模型分步思维,人们就在想,能不能让大模型自己学会这种方法呢?
2、强化学习和自学推理
类似当年的Alpha-Zero,强化学习是让机器自己通过与环境交互并观察结果的方式调整行为策略的机器学习方法,但之前很难用于语言模型。直到斯坦福大学 2022 年提出一种「自学推理」(Self-Taught Reasoner,STaR)方法:先给模型一些例题详细解法,再让模型学着去解更多的题,如果做对就把方法再补充到例题里,形成数据集,对原模型微调,让模型学会这些方法,这也是一种经典的自动生成数据的方法。
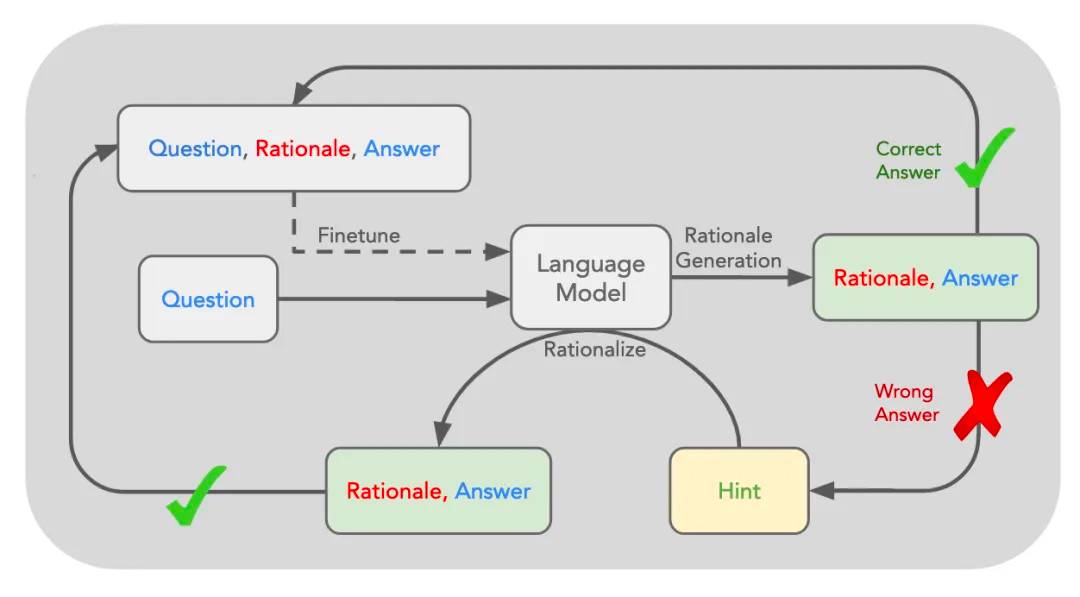
后来基于此又演进出了名为”Quiet-STaR”的新技术,也就是传说中的Q*,翻译过来大概为”安静的自学推理”。核心为在每个输入 token 之后插入一个”思考”步骤,让大模型生成内部推理。然后,系统会评估这些推理是否有助于预测后续文本,并相应地调整模型参数。这种方法允许模型在处理各种文本时都能进行隐含的推理,而不仅仅是在回答问题时。
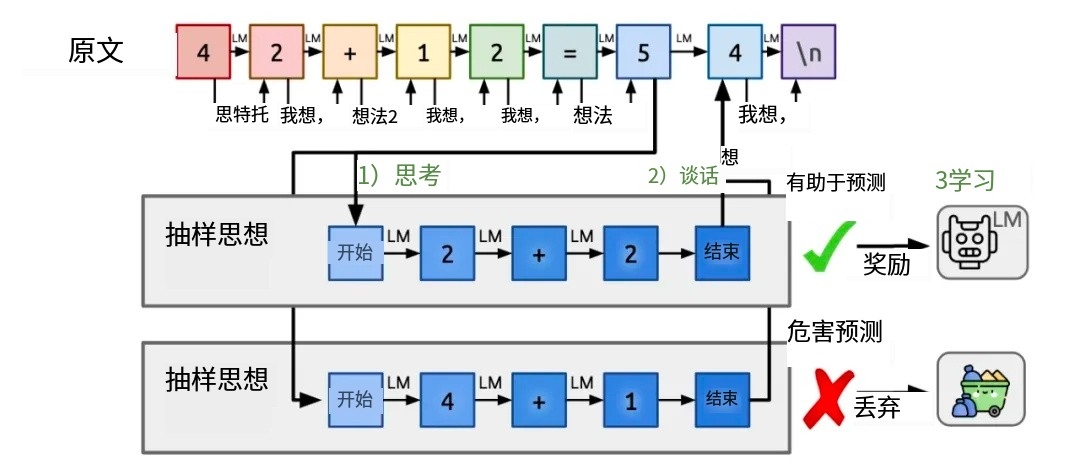
用人话说呢,加入强化学习就是在大模型训练时就教他一些套路(当然应该也是模型自己生成并优选的),思考时直接就按题型选套路分解问题、按步骤执行、反复审核,不行就换个套路,跟通常教小学生普奥的套路类似。但这种自学习机制,由于奖励模型的复杂,所以通常仅在数学和代码领域表现较好。
3、Scaling Law的延伸
以上技术手段结合的后果就是,预训练阶段并没有什么变化,但在推理阶段的计算量大大增加,原来追求的快思考变成了故意放慢速度,以追求更加准确的结果。
OpenAI 提及了自己训练中发现的一个现象:随着更多的强化学习(训练时计算)和更多的思考时间(推理时计算),o1 的性能能持续提高。
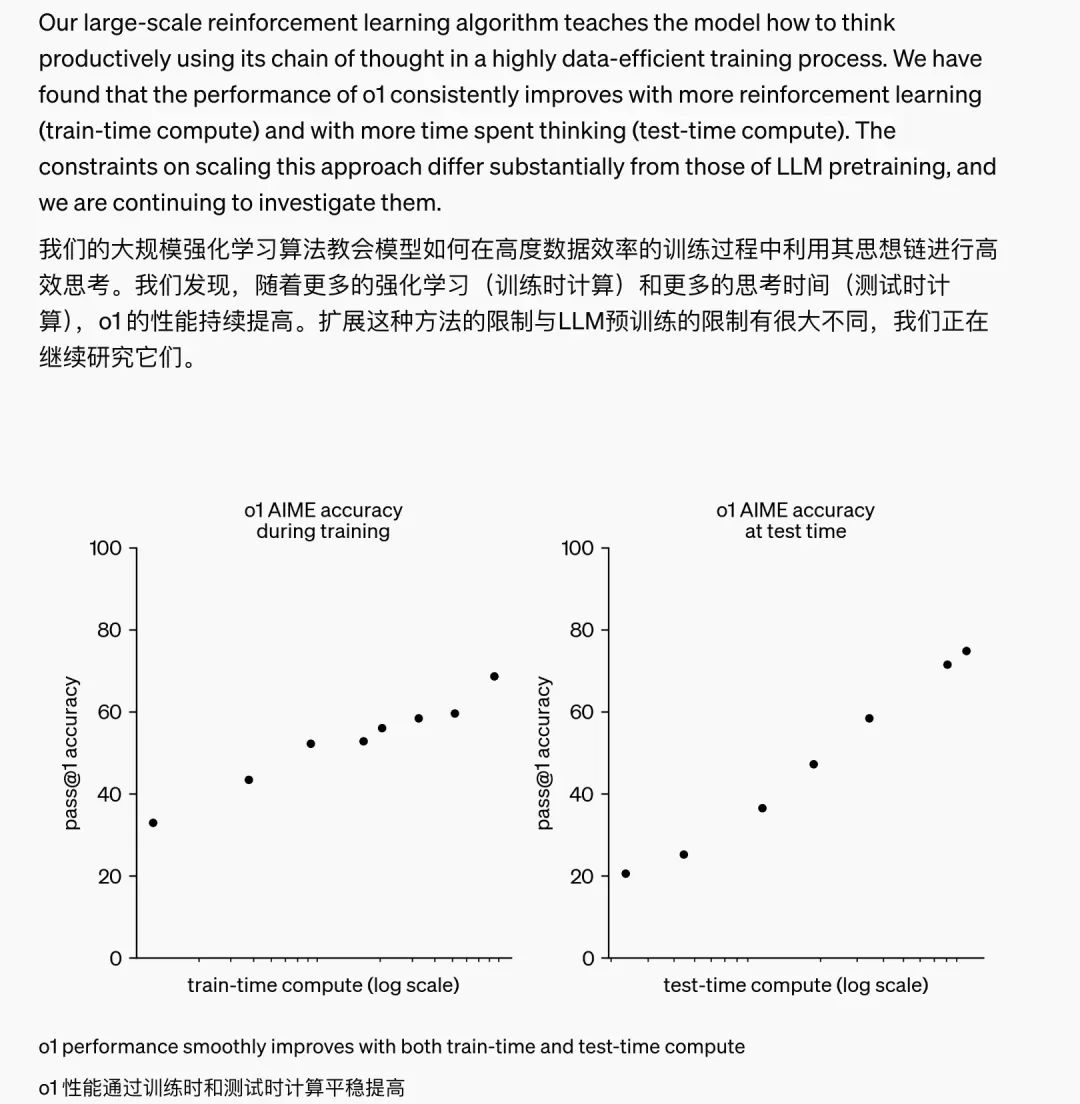
英伟达AI领导者 Jim Fan 在 X 上点评了这一事件的历史意义——模型不仅仅拥有训练时的 scaling law,还拥有推理层面的 scaling law,双曲线的共同增长,将突破之前大模型能力的提升瓶颈。“之前,没人能将 AlphaGo 的成功复制到大模型上,使用更多的计算让模型走向超人的能力。目前,我们已经翻过这一页了。”
可以预见,在预训练边际成本递减的背景下,基于强化学习的推理增强会越来越受到重视并发挥作用,也会有更多的算力被投入到推理阶段,全球人工智能芯片和算力的需求也还会继续增加。
二、小技巧
不可否认,o1代表了人工智能领域的一次重要进步。但细细回顾过去一年奥特曼的言行,以及OpenAI的组织架构和核心团队的变化,不免让人产生一些疑虑:这个故事会不会有些许夸大其词之处?会不会是借助一系列小技巧,来维持公司估值的增长和资源的获取呢?
1、技术壁垒
无论是Sora还是o1,其实都是基于已有科研成果的工程创新,并没有多高的技术壁垒。OpenAI最大的贡献还是坚定而不计成本地率先实践。跟Sora一样,一旦OAI明确了技术方向,工程复现大概率只是时间问题,而OAI在所有方向上卷赢全球简直是不可能完成的任务。况且以这几天全网的测试情况,模型效果只能说差强人意,很多场景下还不如其他工程手段下思维链方法的结果(如Claude3.5),甚至可以说经常只是概率稍大的抽卡,实用价值还很难确定。另外,也许是为了避免友商的窥探和抄袭,或者是因为开放的思维过程存在安全性问题,OpenAI并未向用户开放整个思维链细节,但仍有研究者在很短时间内宣称复现了与之类似的推理能力。
可以想象,后面各大厂商都会开始卷推理,陆续推出“深思熟虑”版的模型,快速拉齐水平,而如果OpenAI后面再没有拿得出手的底牌,仍然难以扭转本轮模型竞赛到顶的困境。
2、成本
去年已经基本完成的模型拖延了这么久才面世,除了众所周知的安全原因外,可能是因为o1和Sora一样,算力消耗过于巨大而并不具备大规模商用的可行性。面对这一挑战,奥特曼团队一直在尝试寻找解决方案。他们等待了很长时间,希望算力成本能够随着技术进步而下降。同时,他们也在全球范围内四处融资,筹集资金来购买或租赁更多的计算资源。然而,即使经过了这些努力,推出的产品仍然单次推理动辄需要数分钟甚至数十分钟,单价高出4o数倍,token消耗也经常会提升数倍。
这些因素导致了一个尴尬的局面:科研贡献暂时远大于商业价值。在这样的背景下,OpenAI的行业地位和估值能否维持,变得相当不确定。高昂的研发和运营成本,加上商业化受阻,可能会影响投资者的信心和市场预期。
3、方法论
如果说前面两点商业视角的质疑对一路引领的OAI有一些不公平,那么这个方法论是不是真的如其所说,能达到甚至超过各STEM领域的“博士水平”,其实也是值得进一步讨论和验证的。从原理上说,这种思路还是在“大力出奇迹”的Scaling Law基础上继续叠加buff,引入类似蒙特卡洛树搜索等暴力方法多路径尝试推理,某种意义上是在用文科方法解决理科问题。类似之前的AutoGPT类应用,面向复杂问题,如果不对思维链的搜索空间进行严格限制和引导,可能会陷入漫无边际的发散,消耗大量算力仍然无法得到需要的结果。
如前文提到,这种方法有些类似面向普通学生的“普奥”中常用的套路式教学,更多依赖记忆和模式匹配,而并非对问题本质的深刻理解和创造性思维。就连9.11和9.8谁大都还要琢磨半天,还有相当大概率答错。这种方法培养出的AI,恐怕更像是一个只会刷题刷分的”小镇做题家”,而非真正具有洞见和创新能力的”博士”,毕竟只有“做题”过程的训练数据好找。
诚然,在现实中,大量的科研工作确实涉及重复性、机械性的任务,这部分工作如果能够由AI来承担,无疑会极大地提高科研效率。但科研的核心仍然在于创新,在于对未知问题的探索和对新知识的发现。这需要的是灵感、创造力和逻辑推理能力,而非单纯的计算能力。
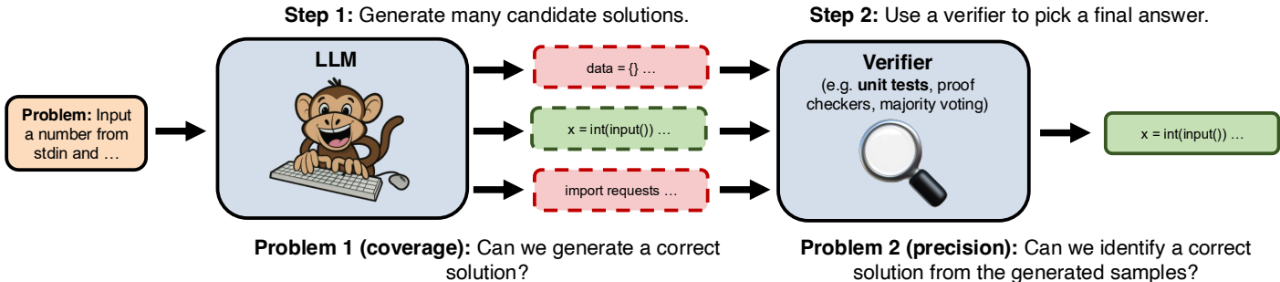
正如《Large Language Monkeys: Scaling Inference Compute》一文所指出的,仅仅通过增加生成样本的数量来扩展推理计算,本质上并没有改变大型语言模型的基本属性,它仍然是一个基于统计概率进行”打字”的”猴子”。要真正实现通用人工智能,实现在科学领域的突破性进展,我们可能需要在算法和架构上寻求更加本质的创新,而不是简单地堆砌算力。
三、新思路
前面是夸也夸了,踩也踩了,但归根到底,笔者认为这些都并非o1的最重要价值。虽然看起来并非OAI眼中的重点,但在材料中多次提到了一个很重要的点,就是o1更适用于科学、编码、数学和类似领域的复杂问题,或者更确切说,是复杂问题中的繁琐工作,尤其是多步归纳或者演绎推理。例如,“医疗保健研究人员可以使用 o1 来注释细胞测序数据,物理学家可以使用 o1 生成量子光学所需的复杂数学公式,所有领域的开发人员可以使用 o1 来构建和执行多步骤工作流程。”
以前我们对人工智能的期待,往往是一个模型既有知识,又有智力,甚至还要有情感和创意,以至于模型的参数量和算力消耗不断攀升。但也许这些目标是要用各种不同的方法去解决,有些还可能是非技术方法。o1的未来也许确实会以某种方式提升原来多模态模型的世界理解能力,但其本身的核心价值,恰恰是一个与世界知识大幅解耦的推理模型。这一点在o1-mini上体现得更加彻底,作为一个低成本的小模型,尤其擅长编程这种不需要太多世界知识的多步严谨推理场景。
人类学习的过程,是先大量学习知识,通过神经元的大量激活和连接形成智力,而具体的知识则往往会被忘记,类似张无忌学太极拳的过程。在解决不同问题过程中,除了以语言理解和逻辑推理能力为基础,还要靠可信知识的查阅和引用,靠灵感创意的涌现,靠情感的人际连接和感应……人工智能也不会仅仅是一个深度学习大模型,而会成为一个越来越“稀疏“而灵活的能力组合,甚至是一套人机协同的新机制。“做题”能力肯定是必要的,但学会了做题,离解决实际问题,还有相当长的距离。
o1的出现,或许预示着这样一个”能力稀疏化”的趋势。未来的人工智能,会从单一的大模型,逐渐演化为知识、推理、创意、情感等不同能力模块的灵活组合,并与人类形成更加紧密和高效的协作。o1只是一个开始,期待百花齐放的未来。

