
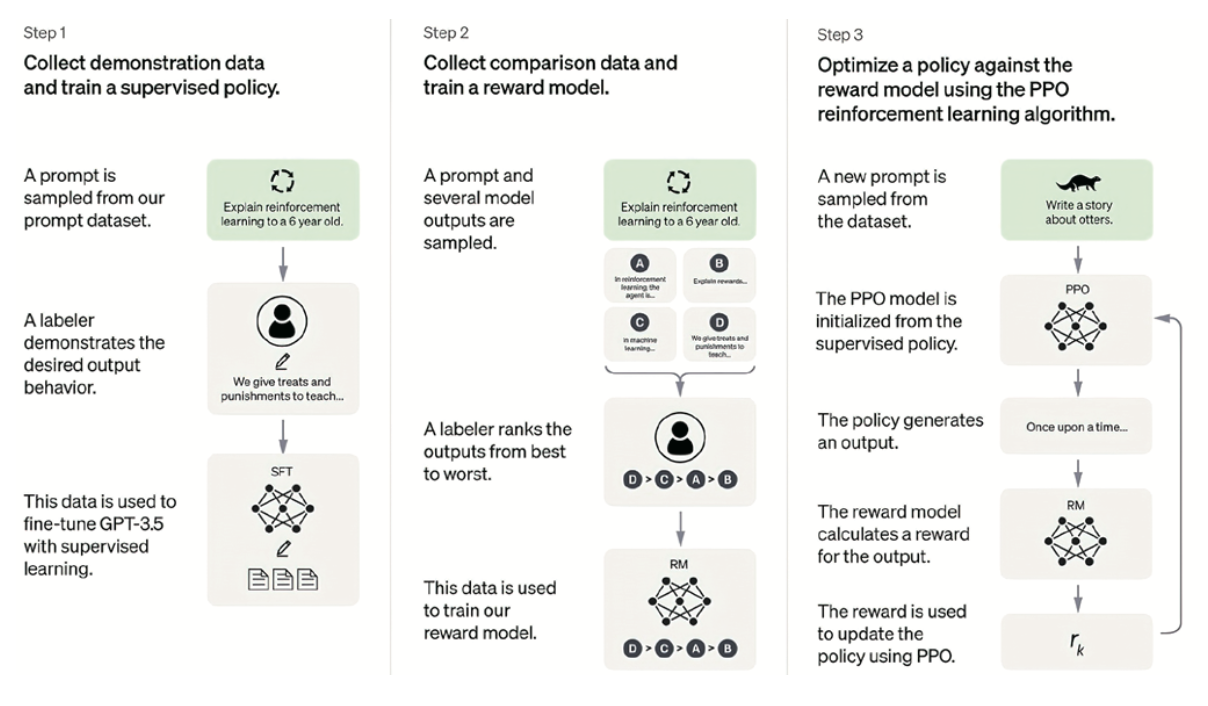
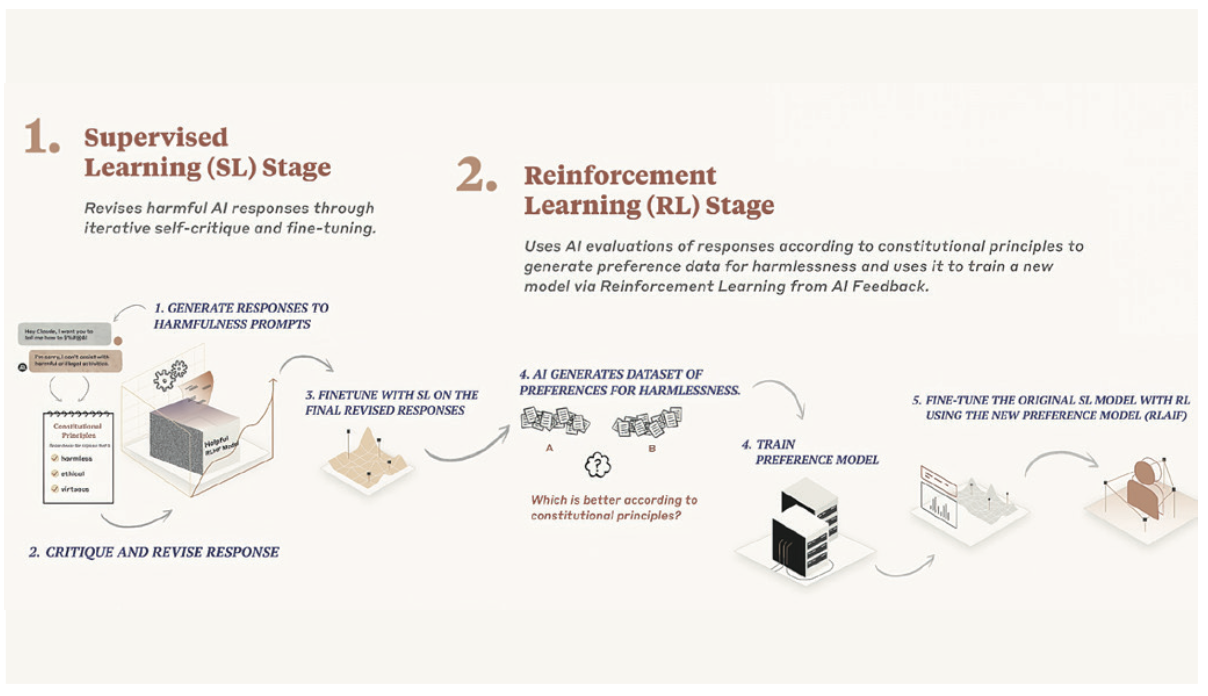

可以说,只有确保AI系统的目标和行为与人类的价值和意图相一致,才能确保实现AI向善,促进生产力发展、经济增长和社会进步。价值对齐的研究和技术实现,离不开广泛的多学科协作和社会参与。政府、产业界、学术界等利益相关方需要投入更多资源来推动AI价值对齐的研究与实践,让人们监督、理解、控制人工智能的能力和人工智能的发展进步齐头并进,以确保人工智能能够造福全人类和全社会。![]()
[1] https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier#introduction
[2] https://time.com/6252404/mira-murati-chatgpt-openai-interview/
[3] https://dl.acm.org/doi/fullHtml/10.1145/3531146.3533088
[4] https://yoshuabengio.org/2023/05/22/how-rogue-ais-may-arise/
[5] https://arxiv.org/abs/1706.03741
[6] https://www.unite.ai/what-is-reinforcement-learning-from-human-feedback-rlhf/
[7] https://venturebeat.com/ai/how-reinforcement-learning-with-human-feedback-is-unlocking-the-power-of-generative-ai/
[8] https://openai.com/research/gpt-4
[9] https://storage.googleapis.com/deepmind-media/DeepMind.com/Authors-Notes/sparrow/sparrow-final.pdf
[10] https://www.anthropic.com/index/claudes-constitution
[11] https://www.ft.com/content/0876687a-f8b7-4b39-b513-5fee942831e8(last visited on May 6, 2023).
[12] https://openai.com/research/language-models-can-explain-neurons-in-language-models
[13] https://mp.weixin.qq.com/s/gSWwj_HzVA3Lq5XZal1a3Q
[14] https://openai.com/blog/introducing-superalignment