



模仿游戏、图灵测试与中文屋实验
二战期间,艾伦·图灵被委任寻找破解德军编码信息的有效方法,在这段时期,他提出了有关计算机科学的基本概念。战后,他投入到人工智能的研究领域,而图灵测试就可追溯至他在1950年发布的一篇论文《计算机器与智能》(Computing Machinery and Intelligence)[1]。
在这篇论文中,图灵首先提出了一个问题:机器能思考吗?(Can machines think?),他紧接着指出这个问题没有讨论的价值,与其在一系列复杂的概念上纠结,不如着眼于更具体的场景。
他提出了一种思想实验:模仿游戏(imitation game),而这个思想实验后来就被演化为“图灵测试”。
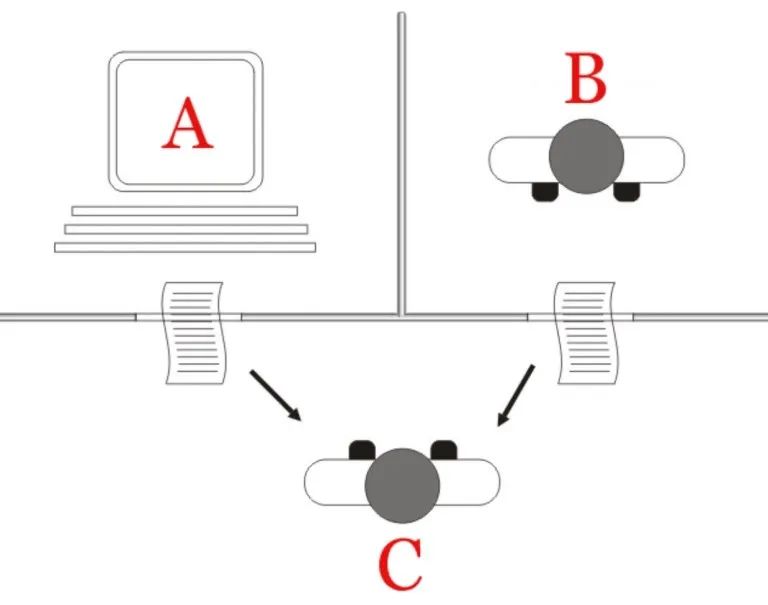
在同一篇文章中,图灵还预测,到2000年,一个普通人区分人和机器的可能性将降到70%甚至更低。这个说法在后续的相关测试中被确立为一项标准,即机器只要骗过30%的测试者,即可被认定通过图灵测试。
图灵测试确实有其进步性。在这篇论文被发表的时间点,人工智能的概念还没有被提出(要等到1956年达特茅斯会议),当时的绝大部分观点认为,人和机器存在本质不同,机器没有感情,更无法像人一样思考。而图灵测试采用了类似于约翰·罗尔斯“无知之幕”的形式,将测试者与测试对象隔离开,并且通过文字而非声音交流,让机器避免了不公平的比较。
正是因为图灵测试对人工智能领域的宰制力如此强悍,所以即便ChatGPT已经大杀四方,人们还是愿意回到原点,念兹在兹已近七旬的图灵测试,似乎唯有这样,才能给这个技术实现“加冕”,赋予合法性。
图灵测试的聪明之处在于,“意识”“思维”“智能”都是难以通过定义来阐释的东西,那索性就不去思辨概念,而是用公认具有思考能力的生物——人类来作为参照物,如果机器的表现与人类难以区分,即可被视为具备了与人类相同的智能。[2]这其实是一种相当结果导向的判别方式——判断机器是否有智能,无需看其内部构造,更无需思辨概念,只需看其行为表现。
图灵的智能观奠定了人工智能计算主义的理论基础。“有智能就是有思维,而能思维就是能计算,所谓计算就是应用形式规则,对(未解释的)符号进行形式操作。”[3]从图灵开始,人类的心灵、智能虽然仍然神秘莫测,但不再只能用思辨的语言去意会,而是可以用定量的语言去描述。由此,计算主义构建了他们的心智模型:人的思维或认知就是一种依照规则进行的纯句法、纯形式的转换过程,而其实践目标便成为,如何建立一台能跟人一样输入输出的机器。
但这种智能观,甫一问世就招致激烈的批判。最主流的批评声音认为,如果仅有形式转换过程,而没有情感、意识、学习能力等,显然无法称之为“智能”。在批评的阵营中,最有代表性的就是“中文屋实验”。
1980年,美国伯克利大学哲学教授约翰·塞尔设计了这个思想实验,证明了通过“图灵测试”的机器并非真正具备智能。他假设有一个只懂英语、完全不懂中文的人被锁进房间,房间内还有一箱中文字片以及指导手册。而房间外是一个毫不知情的人,他向屋内递进字条用中文进行提问,房间里的人按手册指导来挑选字片,并且给出正确答案。从结果来看,房间里的人无疑能成功通过测试,但实际上他对中文一无所知。
塞尔指出,房间里的人就跟通过图灵测试的机器一样,无需理解输入输出字符的含义,只要按照既定规则搬弄字符,就能形成一种具备理解能力的假象。这不是真正的理解,最多是一种扮演行为,并不具备任何思考能力。
中文屋实验挑战了以图灵测试为代表的计算主义对人类智能的建模。它揭示了智能的关键并不在于语法或形式转换,哪怕是通过了图灵测试的计算机程序,也无法证明它是有智能的,它只是在处理语法,而未涉及语义,并不具备真正的意向性。它只是实验中那个坐在房间里的、完全不懂中文的“人”。
图灵测试已经过时
尽管反对者重重,但都没能阻止图灵测试成为人工智能领域的北极星。时间线推移到二十世纪六七十年代,通过图灵测试成为人工智能发展的核心目标。由于图灵测试侧重关注语言互动,这在某种程度上推动了聊天机器人的进步。
进入21世纪,人工智能后来者接力前辈,继续攻克图灵测试,并取得了关键进展。1991年,美国发明家洛伯纳发起图灵测试竞赛,要求人类和计算机分别与裁判团进行25分钟对话,骗过裁判最多的程序获胜。终于,在2014年6月,由俄罗斯团队研发的“尤金·古斯特曼”(Eugene Goostman)在测试中骗过了超过33%测试者,被认定为一个13岁的小男孩。
按照标准,它通过了图灵测试。
尤金·古斯特曼不是孤例。Google推出的虚拟助理Duplex打电话给美发沙龙并成功预约,而对方并不知道她在和电脑对话,也被认为是通过了图灵测试;作曲程序lamus则通过了非语言类图灵测试,250名受测者(其中一半是专业音乐家),只有24%成功区分lamus和人类作曲家的作品。
显然,图灵测试早就不是我们刻板印象里那样坚不可摧,已经被捅成了筛子。但是,这些通过了图灵测试的程序,并没有制造出想象中惊天动地的后果,并产生自我意识,拿起武器反抗人类压迫。相反,它们大多籍籍无名,至少从目前看,通过图灵测试是它们能够达成的最高成就。
按结果导向的思路,图灵测试显然没有任何神奇魔力。越来越多的研究者也逐渐认清这一点,并致力于为这个思想实验祛魅。比如Hayes和Ford在其1995年的论文中,相当毒舌地建议科学家放弃构建“机械异装癖”(让机器模仿人类的一种讽刺说法),他们认为图灵测试的设计有很多歧义、缺陷与漏洞,其标准难以捉摸,无法检测到任何东西,因此图灵测试应该“从教科书转移到历史书”。[4]
其实很容易想见,一个1950年提出的思想实验,怎么会预见到此后七十多年人工智能的发展趋势?在图灵所处的年代,人工智能领域尚未建立,商用计算机还未被推出,当时最先进的阿波罗11号的算力,是智能手机的十万分之一。图灵是世所稀有的天才,但并不是巫师,更不是穿越者,他的思考难免受到时代的局限,而他提出的思想实验也更像是一种直觉,未被严密论证
在图灵测试提出后的这几十年间,人工智能发展为一门前沿学科,产生许多图灵无法想象的进展。比如多模态感知能力,比如决策规划能力,比如在围棋比赛完虐人类选手等等,更别说强大到让世人惊叹的ChatGPT,这些都很难被一个测试所囊括。图灵测试无法体现出这些方面的进步。可以说,关注图灵测试已经没有什么意义。
如亚马逊副总裁兼Alexa首席科学家Rohit Prasad所说,我们更应该关心人工智能的实用性和区别于人类的能力,而不是它在图灵测试的分数有多高。人工智能没有人类一样的即时反应、快速推断能力,但是人工智能的快速计算和信息检索等能力远强于人类,而这些能力才是现代人工智能(包括ChatGPT)的核心所在。[5]
从这个角度说,图灵测试暗含极强的人类中心主义。因为只有人能思考,所以人类成为了“智能”的唯一代言人和坐标系,只有与人类无差别的,才被认定为是拥有“智能”的主体。这是一种极为狭隘的智能观。
同时,图灵测试的规则设计,所导向的是一种欺骗性思路,即AI只要成功“欺骗”过测试者,就可以被视为拥有“智能”。所以,以ELIZA为始源的许多聊天程序专门为欺骗人类而设计,它们会在解决问题时故意犯错,或者有意拖延回答的时间,用一种所谓的“类人行为变异性”(Behavioral variability)来装得更像人类,以求骗过测试者。
这显然是一种扭曲的、没有意义的发展方向,甚至具有极高的伦理风险。大量聊天机器人用于电信诈骗、制造谣言,以及深度伪造(deepfake),都是这种以欺骗为导向的设计思路的产物。
倘若一直对这种欺骗导向的观念顶礼膜拜,只会助推AI向恶的风气愈演愈烈。
ChatGPT时代亟需一种新的智能观
与处理能力有限的人脑相比,AI的处理能力在理论上是无限的,可以无差别处理收集到的全部信息。一旦AI获得意识,它们能够像人类一样交换、分享信息,只不过在效率上是碾压人类的。
作为结果,AI的智能水平将迅速崛起,并会“消灭”掉包含人类在内的低智能主体——这并不是大屠杀,而是与智能手机淘汰传统手机一样的“市场行为”。
当下的人类社会是一个一元论社会,虽然我们常说“万物有灵”,但那只不过是在泛灵论基础上的一种谦辞,真正的现实是,只有人类拥有真正的“智能”与“意识”。如果一旦诞生了拥有意识的另一方主体,建立在一元论基础上的既有一切都会被颠倒重构。人类有史以来所积累的所有道德秩序就会失去最重要的逻辑支点,在这种情况下,人类该如何重构自己的道德伦理体系?人的本质何在,人又何以为“人”?如果世界上有其他外观形式也能够产生意识,人的主宰权威就会泯灭,自身的超验背景也会消失。那么,不再是“万物灵长”的人类又该如何自处?能否接受与创造物共享这个世界?[6]
这种恐慌,是图灵测试被追捧的原因之一。我们小心翼翼地关注着人工智能产生意识的“奇点”时刻,这是一种既恐惧又期待的心理:既希望它到来得晚一点,又好奇它什么时候能到来。
但是,至少从目前的实际表现来看,ChatGPT虽然强大,但离产生自我意识仍然遥远。ChatGPT本质上仍是基于统计的语言模型,它的“思考”,是基于语言模型的运作,它的“创造”,是不同语料的排列组合,它的“回答”,是在先验知识基础上进行加工的产物,并不具备真正自我认知。尽管人类还尚未破解有关意识的秘密,但可以明确的是,再强大的模拟和算力,都无法催生出意识。
在这个问题上,GPT-4比大部分狂热者们更加清醒。我向它提问“ChatGPT是否拥有自主意识?”,它的回答是:
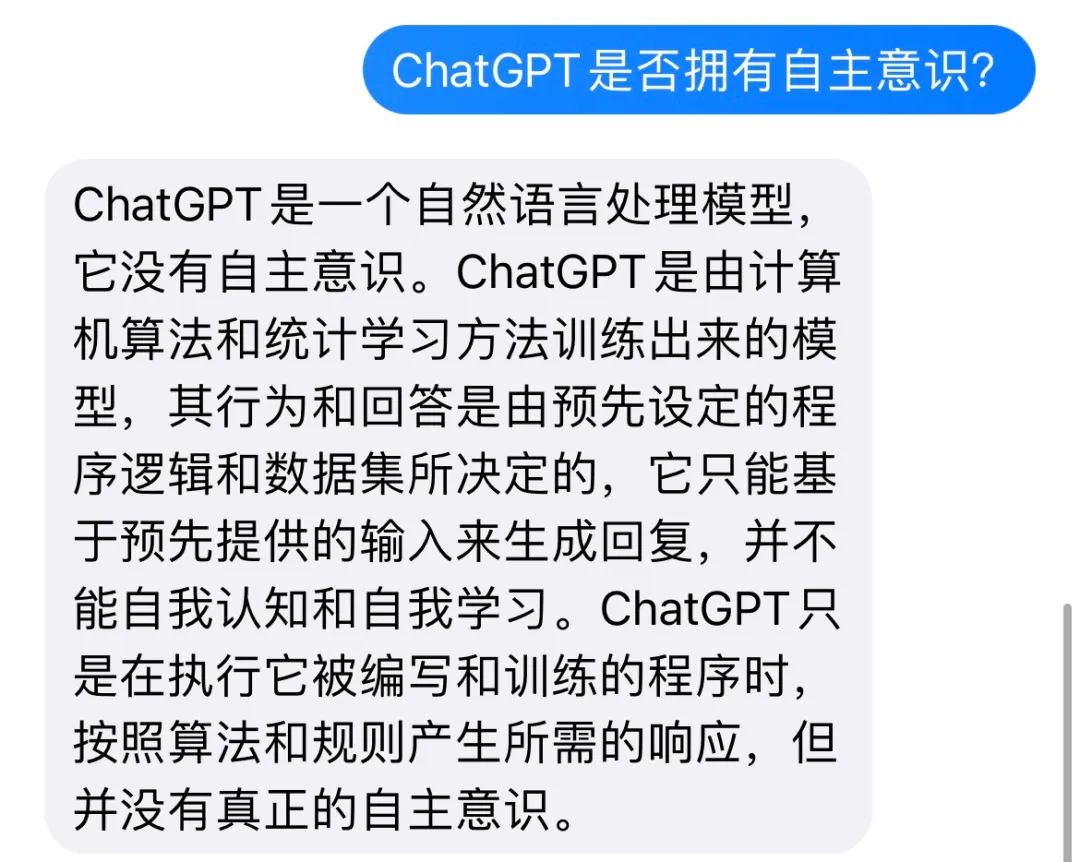
话说回来,即便ChatGPT尚没有意识,但它的智能水平无可否认,哪怕还没能通过“图灵测试”。在七十多年后,在ChatGPT所属的、人工智能迅猛发展的时代,我们需要一种新的“智能观”。
图灵测试代表了一种单一化的智能观,人是智能的标杆,机器只有模仿人并与人难以区分,才被视为拥有智能。如前文所说,这是一种人类中心主义的视角,它武断地否认人类之外的一切智能主体,可能扼杀真正的人工智能。
关键在于,智能并非只有一种,它有许许多多的类型与表现形式。人类的智能是智能,AI的智能也是智能。比如快速计算、信息检索、决策推理等等,这些都是AI区别于人的智能类型。我们要做的是建立新的能力衡量标准,而不是执着于抹平AI与人的差别。不仅如此,这些能力模型,也应考虑AI的伦理道德维度,毕竟,假设有一天我们真的要与有自主意识的AI相处,我们也会希望它是一个正直、可信、有责任心的AI,而不是一个想方设法骗过我们的AI。
https://mp.weixin.qq.com/s/KixhWQPk5-5Ww65yZzy3MA
[3]参见江汉论坛:《“图灵测试” 与人工智能元问题探微》,作者:高新民、罗岩超;
[4]参见Hayes P, Ford K. Turing test considered harmful. In: Proceedings of theinternationaljoint conference on artificial intelligence, Montreal, vol. 1; 1995, p. 972–7.
[5]参见Rohit Prasad本人在fastcompany.com的撰文:
https://www.fastcompany.com/90590042/turing-test-obsolete-ai-benchmark-amazon-alexa
[6]关于人工智能的意识问题在《图灵逝世66年后,AI可以自我思考了吗?》有更多阐述;

