如何在AI全生命周期中防范算法歧视风险?

当前,算法歧视已是AI领域老生常谈的问题,从近年来颇受关注的AI歧视事件来看,这些偏见常见于招聘、司法、贷款、入学、移民等算法评估工具。
例如,继2018年亚马逊的AI招聘工具被发现歧视女性劳动者后,2021年9月,根据哈佛商学院和埃森哲公司的最新报告,在美国,随着每年求职者人数的增加,多达75%的雇主公司开始倾向于使用AI技术(如具有OCR功能的简历扫描软件),来帮助其处理繁杂的简历和挑选候选人。约有2700万“隐形人”(hidden workers)正面临被AI简历工具的自动化决策进行过滤的窘境。
报告显示,这些AI简历工具大多只看重简历的形式内容(如证件资格)而非应聘者所能带来的实际价值,因此将许多潜在的合适人选拒之门外。其中,诸如残疾人员、刑满释放人员、与配偶分隔异地的人员等具有特殊经历的人还会受到AI工具不同程度的排斥。[1]AI偏见可能无处不在,也亟待得到有效的治理和控制。
为此,各界都在致力于探索消除AI偏见的技术和途径,部分组织已取得了一些有益成果。2021年6月22日,美国国家标准技术研究所(NIST)发布《关于识别和管理人工智能歧视的标准提案》(A Proposal for Identifying and Managing Bias in Artificial Intelligence),并向社会公众征求意见。[2]
随后,7月29日,NIST提出制定《人工智能风险管理框架》(Artificial Intelligence Risk Management Framework)并征询各界意见,该AI风险管理框架旨在帮助AI的设计者、开发者、使用者以及评估者更好地管理AI生命周期中可能出现的风险。[3]NIST希望在此基础上推动建立涵盖AI系统整个生命周期的共通性标准和风险管理框架,促进可信、可负责AI理念和技术的实现。
那么,AI在其生命周期中可能存在哪些偏见?产生偏见的原因是什么?我们又应如何识别和减少AI偏见?本文将结合《提案》的内容回答这些问题。
《提案》认为,随着以数据驱动(data-driven)和机器学习为核心的技术路径越来越多地被用于AI的算法决策,AI所蕴藏的歧视性风险也逐渐暴露在真实世界中,引发了人们对于AI歧视的广泛关注。目前,AI系统存在一些常见的歧视性风险,这些风险大多是由数据集和模型的不合理使用而造成的。
首先,在数据集的选择上,AI通常难以对数据的偏见进行标识描绘和管理,原因在于其只能通过可量化、可观察的数据来构建模型和概念。例如,在刑事司法领域,AI可用于被告人的量刑分析和预测(如Compas系统),对于被告人的有罪性(criminality)和人身危险性,AI通常主要根据其累犯记录、年龄以及地区等可测量的数据进行评估。但实际上,任何代码和参数都无法对人类复杂的语义和思维实现完整的概括和表达,也难以通过自然语言处理对人们的思想、情感、语言等感性内容实现完全转换。因此,在从人类语义到计算机语言的编译过程中,普遍存在信息失真和错误等问题。如果输入的数据不准确或是带有偏见,也会导致AI在数据集的训练和决策中产生不公平的输出结果。
其次,在数据集的获取上,目前大部分AI系统在获取数据集时会优先考虑数据是否易于收集,是否存在可获得的数据来源,而非优先判断该类数据集是否合适,能否满足AI应用的功能和目的。因此,AI的研发者和实践者只能随“数据”应变(go where the data is),以数据集内容来决定系统的开发方向,而不是根据系统的实际需求来收集数据。此外,提供给AI系统的数据集也可能与现实中的真实数据存在偏差。这种偏差可能由于数据样本的单一性和片面性所致。例如,若采用网上调查问卷的方式收集数据,那么数据样本只能代表参与调查的网民,而无法涵盖其他领域的群体,将此类数据应用于AI的训练中,将会产生欠缺完整性和科学性的决策结果。
再者,在数据集的训练上,AI系统在训练过程中可能展现出数据集中的历史和社会偏见,或是不当地使用受保护的特征(种族、性别、年龄、地区等)。更进一步而言,即使公众并没有直接与AI系统进行交互,也可能在无意识中受到AI技术和自动化决策系统的影响。例如,人们在申请贷款、入学、住房资格时,相关的历史数据、训练数据或者测量数据将被用于算法模型的分析和预测中,从而产生具有潜在歧视性的决策结果。
最后,NIST认为,未经验证的算法模型也是引发AI偏见的重要来源。尤其是对于那些未经测试和把关即投放部署的AI系统来说,其容易出现系统决策的歧视和错误等问题。NIST通过两个例子来说明此观点:
一是在实践中,在新冠肺炎病毒流行期间,部分机构匆忙部署新开发的AI系统以预测疫情走向以及诊断患者症状,结果发现这类机器大多存在技术方法上的缺陷和偏见;
二是在理论上,目前已有许多文献对AI技术的常见问题进行描述,如概念存疑(questionable concepts)、实践具有欺骗性或未经验证(deceptive or unproven practices)、缺乏理论基础(lacking theoretical underpinnings)等。这些文献提出,对于在招聘、风险评估、犯罪量刑系统等领域进行决策和预测的AI系统,其部署前应当在特定的应用场景中验证自身的有效性(validity)和可靠性(reliability)。这是由于,这些领域的算法决策对人们生活造成的影响重大,因而有必要对其采取合理的验证和保护措施,尽可能减少AI系统在这些领域中的歧视性风险。
总的来说,NIST认为,数据集的内在偏见、存在偏见风险的自动化系统以及使用未经检验的AI技术等,都是引发算法歧视以及导致公众“信任崩塌”的主要原因。为此,NIST提出,可针对AI系统在不同场景下的运作建立统一的AI歧视性风险管理机制,而非针对每个具体使用场景寻找特定解决方案,这将更加富有成效。
“在结果上,应尽可能识别出AI在部署期间蕴含的社会歧视确保AI在决策的准确性和公平性之间应做出合理的权衡与取舍。
建立贯穿人工智能系统生命周期的风险管理系统,有利于确保开发、部署人员对系统进行全过程的追溯和审查。目前,国际上还未对人工智能系统生命周期的技术标准达成一致,仍缺乏通行的共识理念和行业规范,国际标准化组织(ISO)和国际电工委员会(IEC)也已将人工智能生命周期标准的制定提上了日程。
在此趋势下,NIST结合了CoE[4]、OECD等现有文件的相关内容,提出了关于人工智能系统风险管理的三个关键阶段,即预设计阶段、设计开发阶段、部署阶段,并强调要发挥多利益相关方在三个阶段中的参与作用,充分汲取和兼顾不同的反馈意见和研发理念,提升人工智能系统决策的包容性和多元性。
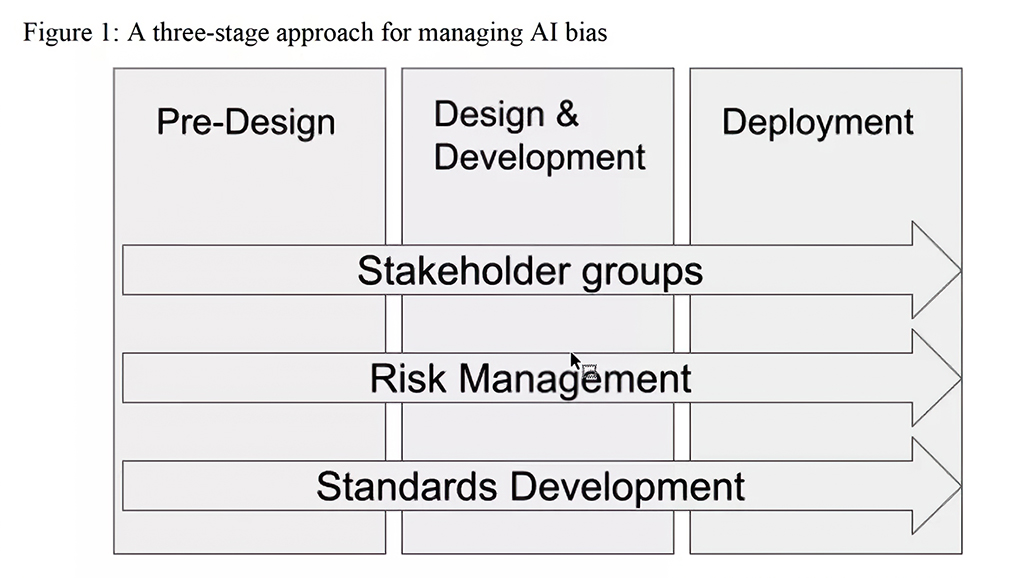
(1)
AI 预设计阶段的潜在风险和解决思路
① 预设计阶段的歧视性风险
NIST认为,AI在预设计阶段可能面临问题表述不清(Poor problem framing)、数据驱动路径导致的虚假关联(spurious correlations from data-driven approaches)、无法建立合理的因果关系机制(failing to establish appropriate underlying causal mechanisms)、整体性的技术缺陷等问题。倘若存在这类问题的AI系统没有经过检验就投放生产和使用,则容易使产品的问题在部署阶段被发现,因而该过程也被称为“fire, ready, aim”(在行动中检验和评估质量)。
NIST认为解决这类问题的最佳方案并不是排除缺陷,而是拒绝部署和使用基于此类AI系统的产品以及设计方案。原因在于,AI系统在设计上的缺陷会直接导致AI偏见的形成,进而加剧公众对此类AI技术的不信任。尤其是对于高风险(high-stakes)的AI而言,其在部署前应经过进行大量的测试和验证程序,以确保技术在应用表现上的有效性和可靠性。
② 解决思路
NIST认为,在预设计阶段减少偏见的有效举措包括以下几个方面。首先,要以解决问题为导向,树立正确的系统研发理念,确保研发者以合乎伦理和道德的方式设计算法。在风险的来源上,若AI的预设计未能充分识别数据集的风险,则可能导致系统在设计和研发阶段使用具有歧视性的数据,从而在将来部署时造成对特定用户群体的歧视。因此,有专家建议,在预设计阶段,研发者在收集和处理数据时不仅应遵循数据最小化原则,还应制定更高的道德标准,通过最小数量的数据集来确保AI系统的模型、方法或技术所使用的数据集是真实的而非虚拟的,从而在预设计阶段从源头上防范AI歧视。
其次,设计者应关注AI在实际运行环境中的未知影响。在AI的开发过程中,研发者的认知通常受到技术解决主义(technological solutionism)的影响,认为技术只会带来积极向善的解决方案。这种认知容易导致研发者陷入单线程的设计思路,即仅仅关注如何对技术或工具的性能进行优化,而忽略了技术在具体应用场景中的实际运作表现,进而出现AI技术与使用场景不兼容的问题,也使得人们理解AI工具决策输出的难度大大增加。[5]
NIST认为,对于存在已知或者潜在歧视的应用领域,为其开发算法决策工具是极具风险的。这是因为在AI的研发和部署过程中,AI通常难以及时地识别和排除自身对用户输出的歧视性或者负面结果。然而,在AI的预设计阶段,研发者很少能未雨绸缪地预见AI在实际操作环境中的潜在偏见和负面影响。因此,研发者在预设计阶段既要关注AI工具的性能,也要考虑AI在实际应用中的表现效果,有效识别和减少算法偏见等负面影响。
再者,应避免对AI产品的夸大宣传和过度营销。NIST认为,研发者在预设计阶段的某些决策也可能对AI系统产生具有伤害性的负面影响,甚至可能被不法分子用来达成一些极端危险的社会目的。如果研发者始终保持对AI系统的盲目乐观和自信,为了营销而过度夸大系统的优势,而非理性、客观地看待其中的安全隐患,将难以对AI系统中的潜在风险和伤害形成有效克制。NIST建议,在一些极端情形下(例如AI工具或应用通过欺诈、伪造的方式欺骗用户),宜采取的做法不是排除此类风险,而是拒绝部署和使用此类产品,从而避免因对用户造成伤害而损害生厂商的声誉。
总的来说,NIST认为,尽管AI的预设计阶段非常关键,但如果研发者在此阶段发现AI系统存在难以解决的技术缺陷,应当确保其经过科学的测试和验证,然后才能投入部署,而非采用先部署后评估的方式,从而避免AI产品在运行期间出现潜在的偏见风险。而对于具有高风险的AI技术,研发者应该保持谨慎、克制的态度。
(2)
AI 设计和开发阶段的潜在风险和解决思路
① 设计开发阶段的歧视性风险
设计开发阶段主要涵盖AI系统的建模、验证、开发等关键过程,其中的参与人员包括软件设计者、工程师以及负责AI风险管理(算法审计、参数评估和验证)的数据科学家等。在这个阶段,软件设计者和数据科学家通常会将精力集中于系统的表现和优化(optimization)上。然而,这种对系统优化的过度关注也会无意间形成AI系统的偏见。
首先,在AI模型的设计和选择上,研发者会倾向于追求模型的准确性。但已有的研究表明,仅以准确性作为模型的选择标准并不是减少偏见的最佳路径。[6]如果不将具体的应用场景纳入模型选择的标准范畴,可能会给特定群体输出有偏见的决策(如医疗资源的不平等分配)。
其次,如果AI系统使用不具有代表性的群体数据来预测个人行为,也可能产生偏见结果。这类偏见又被称为“生态谬误”(ecological fallacy),其在算法中表现为根据某类社会群体的成员特征对个人进行推理和决策(如根据人种来决定入学资格)。然而,这种机制可能在无意中加重某些因素的权重,使得算法决策进一步加剧社会的不平等。考虑到这类潜在的歧视风险,研发者应尽最大责任来设计和开发出防范歧视的方法。
② 解决思路
目前,一些科技公司正在逐步建立内部的操作指南,致力于识别和消除AI决策的潜在歧视,以提高组织内使用AI的可靠性。为了让AI组织更加积极和自觉地识别算法模型的潜在偏见,NIST在《提案》中提到了一种激励机制,即“文化有效挑战”(cultural effective challenge),其旨在为技术人员提供一个充分的评估环境,使之能够针对AI的建模和开发阶段提出问题或进行挑战,帮助研发者从根源上识别出统计性偏差(statistical biases)以及人为决策中的内在偏见。
这种方式的优势在于,让技术人员以类似辩论或者质询的方式开展“头脑风暴”,深入到具体的技术环节中对自己研发的AI技术进行辩护或反思,以此激励研发思路的拓新和转变,更有利于技术人员发现AI系统的潜在风险并找到相应的防范路径。
此外,为了更好地识别和减少组织在应用AI过程中可能导致算法歧视的因素,NIST建议针对特定的应用场景开发相对应的算法模型工具,算法决策目的与特定用例之间的一一对应,避免在用例的范围之外设计和研发算法决策工具。最后,NIST引用了相关研究的观点,认为AI的研发团队应和领域专家、产品终端用户等人员紧密合作,在研发过程中充分考虑多方主体的意见和利益,使得算法工具的决策结果体现出文化的多样性和包容性。
(3)
AI 部署阶段的潜在风险和解决思路
部署阶段(deployment state)是指用户与已开发的AI系统进行交互的过程。NIST指出,这个阶段的利益相关者(stakeholder)主要是基于职业需求而使用AI应用的各类用户,包括领域专家、操作者、控制者以及为AI的输出提供解释和支持的决策者等。
① 部署阶段的歧视性风险
NIST指出,AI部署阶段的问题表现为,许多AI工具在进入部署前通常省略了专家审核这一步骤,而直接投放市场进行部署和应用,以向终端用户提供AI技术服务。但如上文所述,这同时也会导致AI工具在实际运作背离其设计初衷而输出偏见结果。此外,即使对于没有直接使用AI工具的公众而言,也可能会受到AI部署的影响,具体表现为用户个人权益遭致减损的风险:
一是用户数据被滥用的风险,AI在建模时会广泛地使用个人数据进行训练,但有些数据在未经用户本人同意和承认的情况下被使用,因而存在用户数据权益被侵犯的风险;
二是AI决策的差异化风险,即算法可能根据用户的地理位置、职业类型而生成不同的决策结果。国外的研究显示,在出行打车软件中,定价算法可能对低收入和非白人区的乘客收取更多的上下车费用,从而导致AI的差异化影响(disparate impact)。
令人担忧的是,随着AI技术和工具广泛应用到人类社会,类似具有广泛性、系统性的歧视风险可能将永久存在于AI算法的决策路径中,这意味着无论人们是否直接使用AI,无论是否同意接受AI的决策,都将或多或少地受到AI歧视结果的影响。因此,AI在部署阶段的歧视性风险尤其值得注意和防范。
在诸多的歧视风险来源中,NIST认为应当格外重视AI在部署阶段可能出现的环境偏差,特别是AI的预期环境和实际环境之间的偏离。对于那些在设计和部署上欠缺决策精准性,或者决策路径过于狭隘的AI工具,其存在的偏离风险可能会随着用户与AI之间的交互而日益暴露出来。例如,如果研发者没有为AI的行为偏差(activity biases)设置补偿机制,算法模型在部署中更容易根据活跃用户的数据进行训练,而忽略潜在的非活跃用户的使用特征。当算法模型“投喂”的数据都来自活跃用户时,意味着AI将优先考虑该类用户的喜好和习惯,而忽略了其他用户的利益,进而形成数据集的遗漏性偏差(omission bias)。举例而言,国外STEM(科学、技术、工程和数学)领域的广告更容易被男性观众欢迎,因此算法会基于市场投放效益的考虑,使得作为潜在受众的女性几乎很少看到此类广告,这就是AI歧视的最佳例证。[7]
NIST认为,AI之所以会出现环境偏差,其原因之一在于,AI从预设计到设计研发、部署等阶段都具有不同的目标和任务,研发者的关注点也会随着AI生命周期的三个阶段而有所转变。具体来说,预设计阶段的关注点是如何利用技术来解决实际问题,推广产品以及在新领域中取得创新;研发阶段的关注点是如何打造、测试以及实施技术。
除了关注点的转变,不同参与者在使用AI上的认知水平也会影响其对算法决策的理解和信任。NIST指出,随着技术进入部署阶段,这种认知偏差可能使得AI出现非预期的表现,甚至将引起人们的质疑和不信任。例如,对于预测和分析大学入学资格的AI而言,AI决策终端的操作者往往同时又是指出算法存在种族歧视的“吹哨者”。一些入学面试官表明,他们并不了解这些由AI预测的入学资格分数是如何计算和生成的,部分面试官甚至认为AI的评分并不能完全真实地反映出学生的个性化特征,因此他们不会轻易相信这些预测分数的准确性。[8]
为此,NIST进一步分析了上述问题出现的原因,认为这是由行业专家和AI开发者之间缺乏共同语言所致,如入学资格的评审专家无法理解AI研发者的设计逻辑,AI研发者没有意识到技术在实际运行过程中可能会被改变用途,且每个用户对于AI模型的输出结果都可能存在解释和理解上的差异,这将使得AI技术在“建”和“用”之间形成沟通上的屏障。
② 解决思路
如上所述,NIST在《提案》中对在AI系统生命周期的三个阶段中可能出现的环境偏差进行了深入的分析,指出AI在生命周期中存在不同程度上的性能差异,也会使得AI的终端用户和开发者分别产生对AI决策的不同理解。整体来看,AI的部署阶段存在环境偏差、AI参与者的理解偏差、用户对自动化技术的过度信任(automation complacency)等容易引发算法偏见的因素,如果缺乏足够的关注和重视,AI决策的歧视性风险将会日益凸显和加剧,可能给用户或者社会造成严重的负面影响。
为此,NIST针对AI部署阶段的各类提出了相关的缓解措施。在机制上,最关键的是要对上述部署过程中可能出现的环境偏差进行监测和审计,确保AI生命周期潜在风险的可视化和可追溯。在技术上,研发者可采用反事实解释技术(counterfactual fairness)来消除AI在实验环境和现实部署环境之间的偏差。在结果上,应尽可能识别出AI在部署期间蕴含的社会歧视,确保AI在决策的准确性和公平性之间应做出合理的权衡与取舍。可以预见的是,为上述问题制定完善的AI歧视性风险管理标准将是未来AI产业重点关注和攻关的方向。
总而言之,NIST认为,导致AI决策出现歧视的原因具有复杂性和多样性,涵盖了AI生命周期的三个阶段,包括数据集的隐性偏见、算法模型欠缺检验、AI运行环境偏差、AI参与者的理解偏差等等。
NIST认为,AI歧视性风险管理的最终目标不是实现零风险(实际上也无法做到),而是在AI生命周期中有效识别、理解、衡量、管理和减少AI的潜在偏见。为此,NIST提出,管理AI系统的歧视性风险应从以下维度出发,一是制定与AI偏见的术语、测量以及评估相关的技术标准和指南;二是基于特定应用场景(context-specific)的方式管理和识别AI偏见,即对于AI在不同建模阶段中可能出现的歧视风险,需要在特定的运行环境下对其进行识别和防范;三是在设计、开发和部署AI过程中,应当兼顾研发者、部署人员以及终端用户等利益相关者的意见,在开发算法模型和构建训练数据集时充分考虑各方利益,以提高AI决策的包容性和多元性,推动可负责、可信任AI的实现和落地。![]()
[2] https://www.nist.gov/artificial-intelligence/proposal-identifying-and-managing-bias-artificial-intelligence-sp-1270
[3] https://www.nist.gov/itl/ai-risk-management-framework
[4] IT Modernization CoE, CoE Guide to AI Ethics, General Services Administration, n.d.
[5] E. Moss, J. Metcalf, Ethics Owners, Data & Society. (2020).
[6] J.Z. Forde, A.F. Cooper, K. Kwegyir-Aggrey, C. De Sa, M. Littman, Model Selection’s Disparate Impact in Real-World Deep Learning Applications, ArXiv:2104.
[7] A. Lambrecht, C. Tucker, Algorithmic Bias? An Empirical Study into Apparent Gender-Based Discrimination in the Display of STEM Career Ads, SSRN Journal. 65 (2019) 2966–2981.00606 [Cs].(2021).
[8] T. Feathers, Major Universities Are Using Race as a “High Impact Predictor” of Student Success – The Markup, The Markup. (2021).
