




算法黑箱:从奥巴马“变”成白人说起
打码容易去码难,这条互联网定理似乎将成为历史。
2020年,美国杜克大学的研究者提出一种新型算法,名为PULSE。PULSE属于超分辨率算法,通俗意义上讲,它是一款“去码神器”,经过运算与处理,能够将低分辨率、模糊的照片转换成清晰且细节逼真的图像。按照原论文描述,PULSE能够在几秒钟的时间内,将16×16像素的低分辨率小图放大64倍。
如果仅仅是放大分辨率,似乎没有太多值得称道的地方,毕竟类似的算法早已经出现。更为关键的是,PULSE可以定位人物面部的关键特征,生成一组高分辨率的面部细节,因此,即便是被打了马赛克的人脸图像,其毛孔毛发、皮肤纹理也能被清晰还原。

图 经PULSE处理过的打码图片
图片来源:论文《PULSE:Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models》,论文原地址:https://arxiv.org/pdf/2003.03808.pdf
简单来说,PULSE的原理为:拿到一张低分辨率的人脸图像之后,首先利用StyleGAN(对抗生成网络)生成一组高分辨率图像,接着,PULSE会遍历这组图像,并将其对应的低分辨率图与原图对比,找到最接近的那张,反推回去,对应的高分辨率图像就是要生成的结果。

图:PULSE图片处理机制示例
图片来源:论文《PULSE:Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models》
但问题也就在于此,这款“去码神器”所生成的人脸图像看似逼真,但实际上只是一种虚拟的新面孔,并不真实存在。也就是说,PULSE生成的高清人像,是算法“脑补”出来的作品,这也就是为何研究者会强调这项技术不能应用于身份识别。
但是,永远不要低估网友的好奇心与行动力。有人试用了PULSE之后,发现美国前总统奥巴马的照片经过去码处理,生成的是一张白人的面孔。而后又有许多人进行了相似的测试,结果无一例外——输入低清的少数族裔人脸图像,PULSE所生成的都是具备极强白人特征的人脸照片。在种族平等成为焦点的舆论环境中,这件事很快引起轩然大波。
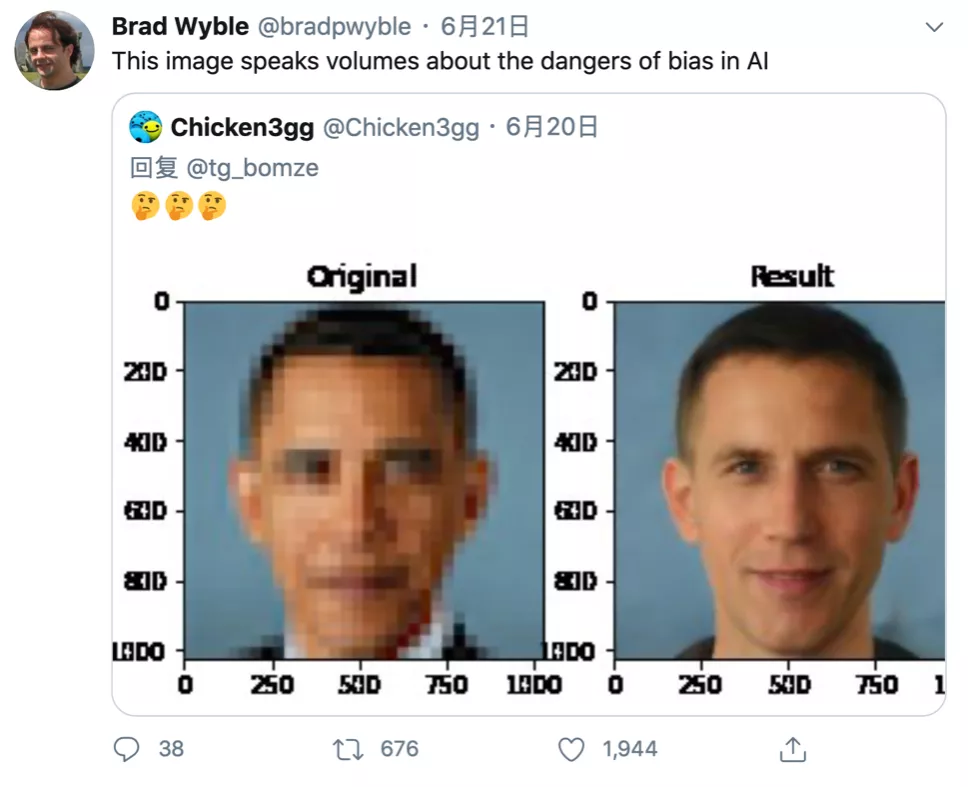
图:奥巴马照片经PULSE处理为白人男性面孔 图源Twitter@Brad Wyble
按照一般经验,出现这种情况,肯定是训练算法所选用的数据库出现了问题。正如PULSE的创建者在GitHub上所解释的:“这种偏见很可能是从StyleGAN训练时使用的数据集继承而来的。”人工智能领域的标杆性人物Yamm LeCun也被卷入到相关的讨论之中,他同样认为机器学习系统的偏差源于数据集的偏差。他指出,PULSE生成的结果之所以更偏向于白人,是因为神经网络是在Flickr-Faces-HQ(FFHQ,人脸图像数据集)进行训练的,而其中大部分的图像素材都是白人照片。
图:Yann LeCun的推文引发了一场骂战(原推文已删除)
“如果这一系统用塞内加尔的数据集训练,那肯定所有结果看起来都像非洲人。”
LeCun本来是为了解释算法偏见生成的原理,但他没能想到,最后这句打趣的话,被指有极强的种族歧视色彩,于是他被卷入一场长达数周的骂战之中。之后,LeCun不得不连发17条推文阐述逻辑,仍然不能服众,最后以公开道歉收场。
倘若事情到此为止,也就没有什么特殊性可言,但事情不是那么简单。在对LeCun的批评声音中,一部分学者指责其片面地理解AI的公平性。譬如AI艺术家Mario Klingemann就认为,问题的出现应该归因于PULSE在选择像素的逻辑上出现了偏差,而不全是训练数据的问题。他强调自己可以利用StyleGAN将相同的低分辨率奥巴马的照片生成非白人特征的图像。
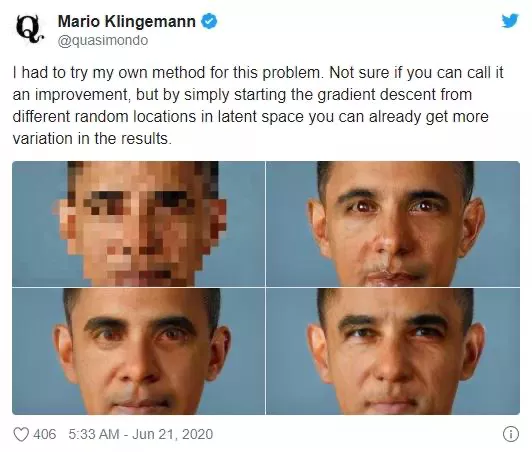
图:AI艺术家Mario Klingemann利用StyleGAN将低分辨率奥巴马的照片生成非白人特征的图像
“对于一张低分辨率图片来说,可能有数百万种高分辨率虚构人脸,都能缩略到相同的像素组合模式”,Mario解释称。这就好比一道数学题可能有很多种解法,在每一种都能得出正确答案的情况下,选择哪种解法,取决于做题的人。如果PULSE更好地改善选择逻辑,就能避免或降低StyleGAN偏见的影响。
距离这一风波已经过去一段时间,时至今日,究竟是哪个环节出现问题依旧没有定论,数据库,抑或是算法本身?
但能够确定的是,这已经不是算法第一次出现偏见。
2016年,美国司法犯罪预测系统COMPAS被指会高估黑人的再犯罪概率,并且大大低估白人的再犯罪概率;2015年,谷歌图像识别系统将黑人识别为“大猩猩”,尽管引起轩然大波,但直至2018年,谷歌都仍未完全修复这一漏洞,只是将灵长类的标签从系统中移除,并称“图像识别技术还不成熟”。
算法偏见是算法诸多社会问题中最有代表性的一个,但一直都没有有效的解决方法。类似事件阻碍着人机互信,也因此成为人工智能发展的绊脚石。
而此类问题之所以根深蒂固,则源于算法的不可解释性。长期以来,人与AI的相处模式就是人类提供数据集,设定程式,而AI负责生成内容、输出结果。换句话说,算法的内在运算机制就像一个黑箱一样,如何运作并不能为人所知,而我们只能接受它的结论。但过程中就可能产生类似于算法偏见的问题,由于算法的黑箱性,我们不会知道究竟是哪个环节出现了问题,纠偏十分困难。
当下,人工智能正在以前所未有的广度和深度参与到我们的工作生活之中,算法的黑箱性也就引发越来越多的担忧与质疑,在特定的文化语境中,伴之产生的安全风险、隐私风险以及更为广泛的算法歧视、算法偏见等问题也愈发尖锐。
2018年,AI Now Institute发布的一份报告(AI NOW Rsport 2018)甚至建议称,负责司法、医疗保健、社会福利以及教育的公共机构应避免使用算法技术。算法的不可解释性逐渐演变成阻碍算法被社会层面所认可的关键性因素。
打开黑箱:谷歌的X AI计划与
模型卡(Google Model Cards)
算法黑箱效应所具备的种种风险,在不同程度上指向了算法的可解释性问题。从2016年起,世界各国政府及各类非官方社会组织就开始极力吁求加强AI的可解释性。
美国电气和电子工程师协会(IEEE)在2016年和2017年连续推出《人工智能设计的伦理准则》白皮书,在多个部分都提出了对人工智能和自动化系统应有解释能力的要求。
美国计算机协会、美国公共政策委员会在2017年初发布了《算法透明性和可问责性声明》,提出了七项基本原则,其中一项即为“解释”,希望鼓励使用算法决策的系统和机构,对算法的过程和特定的决策提供解释。
2018年5月25日正式实施的欧盟《一般数据保护条例》(GDPR)则被认为正式确立了算法解释权。
与此同时,随着愈发意识到AI算法对日常决策的关键影响,消费者也越来越重视数据的使用方式,并要求算法更大的透明度。
正是在社会舆论与官方政策的双重压力下,以谷歌为代表的科技公司开始致力于提高算法的可解释性,“可解释性的AI”计划(Explainable AI)也就在此背景中被推出。这项简称为“X AI”的计划,其本身的目的便是推进AI模型决策的透明性。
早在2017年,谷歌就将其官方战略设定为“人工智能至上”,X AI无疑是这一愿景的一部分。作为人工智能行业的先行者,如何使AI去黑箱化,使其被更广阔的用户所接受,无疑是谷歌需要解决的重要挑战,也是其必须履行的责任。
围绕“可解释性AI”的主线,谷歌推出了一系列技术举措。2019年,谷歌推出可解释人工智能白皮书《AI Explainability Whitepaper》,对谷歌AI平台上的AI可解释探索与实践进行了介绍。同年11月推出的Google Model Cards便是其中较有代表性的一项技术,也表征着谷歌在可解释性领域的最新进展。
Google Model Cards是一种情景假设分析工具,它的功能是为算法运作过程提供一份解释文档,使用者可以通过查看该文档,来了解算法模型的运作原理及性能局限。
正如我们在食用食物之前会阅读营养物质成分表,在路上行驶时会参考各种标志牌来了解道路状况,Model Cards所扮演的角色,便是算法的“成分表”与“标志牌”。
这反过来也提醒我们,即便对待食物或驾驶都如此谨慎,算法在我们的工作与生活中扮演着愈发关键的角色,我们却在没有完全了解它的功能与原理的情况下就听从其安排。算法在什么条件下表现最佳?算法有盲点存在吗?如果有,哪些因素影响了它的运作?大部分情况下,我们对这些问题都一无所知。
在某种程度上,人之所以无法与算法“交流”,是因为后者的复杂原理,更进一步说,这是由于人与算法或更广义的AI采用不同的“语言”。人类使用高阶语言进行思考和交流,比如我们在形容一个事物时往往会用颜色、大小、形状等维度的形容词。而算法关注低阶要素,在它的“视阈”里,一切元素都被扁平化为数据点,方便其考察不同特征属性(Feature Atrribution)的权重。

以图像识别为例,对于算法来说,一幅图像中的每个像素都是输入要素,它会关注图片中每一个像素的显著程度并赋予相关数值,以此作为识别的依据。对于人来说,就显然就不可能用“第五个坐标点的数值是6”这样的方式来进行判定。
这种不可通约性阻碍着人与AI的对话。而可解释性AI的初衷就是使人类,尤其是那些缺少技术背景的人更容易理解机器学习模型。
模型卡(Model Cards)就是以人类能够看懂的方式来呈现算法的运作原理,它实现了两个维度的“可视化”:显示算法的基本性能机制;显示算法的关键限制要素。
换言之,模型卡主要回答了这样一些问题:目标算法的基本功能是什么?该算法在什么情况下表现最好?何种因素阻碍着算法的运作?这些内容的可视化帮助使用者有效利用算法的功能,并避免其局限性。如果说算法是一盒药物,那么模型卡就是说明书,包含适应症状、药物成分、不良反应等内容。
这项诞生于2019年底的技术尚未得到大规模落地应用。但谷歌在其主页上提供了关于模型卡应用的两个实例“人脸识别(面部检测)”和“对象检测”,以展示它的运作原理。
在人脸识别为例,模型卡首先提供的是“模型描述”(Model Description),即算法的基本功能。根据示例,可以看到人脸识别算法的基本功能就是“输入”(照片或视频)、“输出”(检测到的每个面部及相关信息,如边界框坐标、面部标志、面部方向以及置信度得分等)。
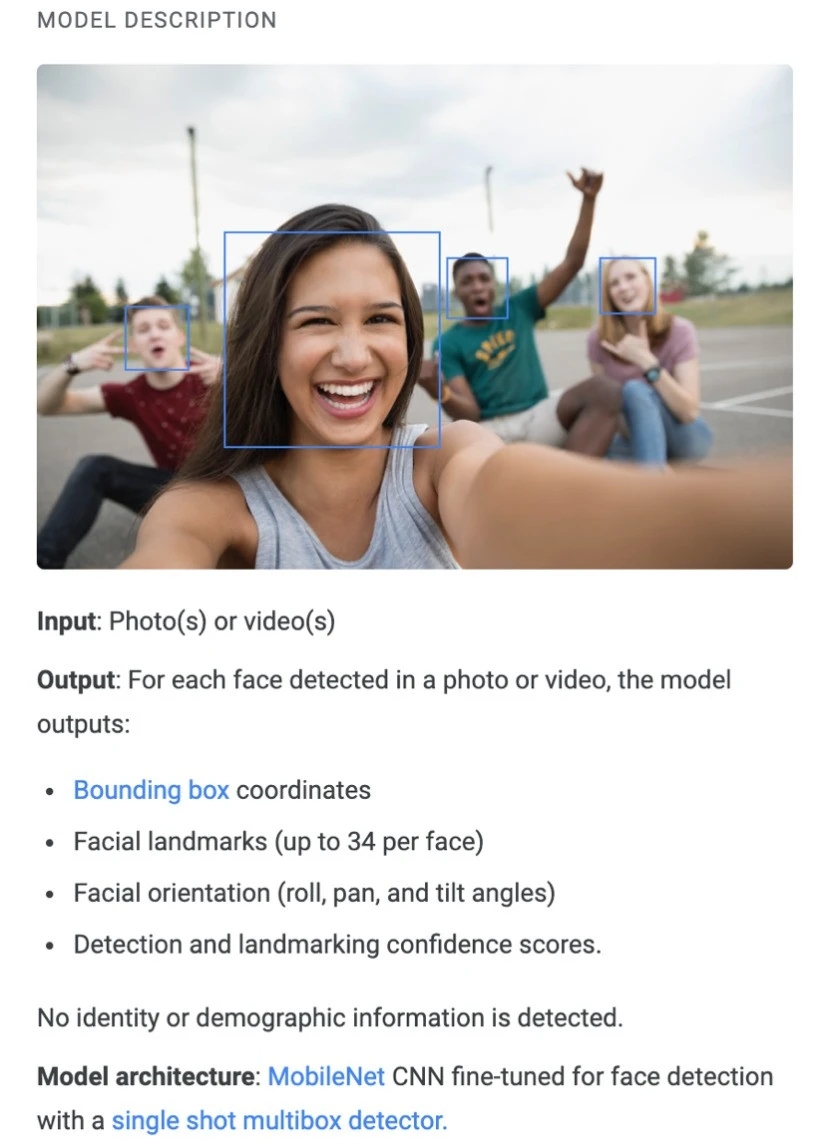
图:模型卡应用于人脸识别的工作原理
而“性能”部分则显示了识别算法在各种变量下的表现,例如面部大小和面部朝向,以及人口统计学变量(如感知肤色、性别和年龄等)。模型卡从与算法训练数据不同的数据源中提取评估数据集,以此有效检测算法的真实性能。
“局限性”则列举了可能影响模型性能的因素,比如脸型大小(距离相机较远或瞳孔距离小于10px的面孔可能无法被检测)、面部方向(眼、鼻、口等关键的面部标志应处于正面)、灯光(照明不良的脸部可能无法检测)、遮挡、模糊、运动等,这些因素会影响人脸识别的效果。
整体而言,模型卡通过提供“算法成分表”的方式,向研究者或使用者展示算法的基础运行原理、面对不同变量的性能和局限所在。其实,对于模型卡的想象力远可以超越谷歌提供的两个案例,其他算法模型也可以采用模型卡对性能进行分析及展示,比如用于语言翻译的模型卡可以提供关于行话和方言的识别差异,或者测量算法对拼写差异的识别度。
一种让普通人理解AI的可行性探索路径
模型卡详细说明了预先训练的机器学习模型的性能特征,并提供了有关其性能和限制的实用信息。谷歌表示,其目的是帮助开发人员就使用哪种模型以及如何负责任地部署它们做出更明智的决定。
目前,模型卡的主要应用场景是谷歌云平台上的Google Cloud Vision,后者是谷歌推出的一款功能强大的图像识别工具,主要功能就是学习并识别图片上的内容。Google利用在大型图像数据集上训练的机器学习模型,开发人员可以通过调取这个API来进行图片分类、以及分析图像内容,包括检测对象、人脸以及识别文字等等。而模型卡则为Google Cloud Vision面部检测和对象检测功能提供了解释文档。
对于技术人员来说,可以借助模型卡来进一步了解算法的性能和局限,从而能够提供更好的学习数据,改善方法和模型,提高系统能力。但模型卡的作用绝对不仅限于此,它提供了更为宏大的想象空间。值得一提的是,近年来除了Google,Facebook、IBM等大公司都推出了免费的技术工具,开发人员可以运用此类工具来检测AI系统的可靠性和公平性。
对于行业分析师和媒体记者来说,他们可以根据模型卡了解算法,从而更容易向普通受众解释复杂技术的原理和影响。
而随着与模型卡类似的技术思路得到更广泛开发和应用之后,可以进一步使普通人从算法的透明性中获益。比如,当人们向银行申请贷款时,银行所使用的大数据算法会对其进行信用评分,进而决定是否能够获得贷款以及贷款额度大小。当一个人申请贷款却遭到系统的拒绝,往往只会收到简单的提示,比如“由于缺乏足够的收入证明,而拒绝了你的申请”。但具备算法常识的人都会知道,运算过程不会是一维的,导致最终决策的是算法模型的特定结构及部分要素的权重。而参照模型卡,普通人就可以根据算法侧重的要素来强化某些维度上自己的表现。
模型卡甚至可以帮助发现并减少算法偏见、算法歧视等问题。例如,在基于人脸识别的犯罪预测系统中,算法在不同人群的识别上是否表现一致,还是会随着肤色或区域特征的改变而产生不同的结果?模型卡可以清晰地展现这些差异,让人们清楚算法的性能及局限所在,并且鼓励技术人员在开发过程中就考虑这些影响。
除了模型卡,在可解释性AI这项工作上,谷歌有更多的表现,比如在Google I/O 2019开发者大会上发布的一项技术TCAV(概念激活向量测试)。与模型卡有所不同,TCAV所侧重的是呈现不同因素在识别算法运作中所占的比重。比如识别一张图片上的动物是否是斑马,TCAV可以分析哪些变量在识别图像时发挥了作用,以及各自发挥了多大的重要性,从而清晰展示模型预测原理。由结果可见,在各项概念中,“条纹”(Stripes)占据的权重最高,“马的形体”(Horse)次之,“草原背景”(Savanna)的权重最低,但也有29%。

图:TCAV的工作原理示意
无论是模型卡,还是TCAV,它们都代表着一种将算法的可解释权利交由社会大众的努力路径,进而达到规制算法权力、缓和算法决策风险的目的。这是它们的创新性所在,也是社会价值所在。
正如前文所述,对于算法的恐惧,不仅仅是一个技术层面的问题,更是社会意识层面的问题——人们天生对陌生事物具有恐惧情绪。在这种情况下,以推进人与AI对话的方式打开算法黑箱,无疑可以打消种种疑虑,增加人们对算法的信任,从而为人工智能更大范围普及开辟前路。随着算法深入到更广泛的领域,可解释性AI这项工作会有更大的前景。
这对国内算法技术的发展也有着切实的启发意义。比如,内容推荐算法遭受着“信息茧房”“意见极化”等种种质疑,很多科普方面的努力收效甚微,技术壁垒仍阻碍着普通用户接近算法。如果能借助模型卡,以一种更友好、清晰的方式展示推荐算法的原理、性能以及局限,无疑能够增进人们对它的理解。
所以,以模型卡为代表的“可解释性AI”更像是一种对话方式。它不仅仅促成技术与技术人员之间的对话,而且也促成了专业人士与普通人的对话。算法的可解释性提高之后,开头提及的LeCun与网友的骂战就会大大减少,因为那时候,人人都知道算法的偏见来自何种因素、数据集和识别方式,或许在引起争议之前,大多数问题就能够解决掉了。
可解释性AI,也没那么容易
到今天为止,“可解释性AI”已经提出了一段时间,但实际上并没有掀起太大的波澜。或许在理想的“实验室”环境下它大有可为,但放诸现实语境中,算法可解释性的推进还有一些阻碍。对于算法可解释权本身的存在及正当与否,无论在理论维度还是实践维度都存在着重大的分歧。
首先,算法太过复杂以至于无法解释。要知道,大多数具备良好性能的AI模型都具有大约1亿个参数,而这些参数往往都会参与到决策过程之中。在如此众多的因素面前,模型卡如何可以解释哪些因素会影响最终的结果?如果强行打开“算法黑箱”,可能带来的结果就是牺牲性能——因为算法的运作机制是复杂、多维度而非线性的,如果采用更简单、更易解释的模型,无疑会在性能方面作出一些取舍。
其次,尽管AI的可解释性重要程度很高,来自社会多方的压力成为可解释性AI的推进动力。但对于这项工作的必要性与最终的可行性,也要打一个问号。因为人类的思维与决策机制也是复杂而难以理解的,即便在今天,我们几乎也对人类决策过程一无所知。倘若以人类为黄金标准,还如何期望AI能够自我解释?如果是在非关键领域,AI的可解释性又有多重要?
Yann LeCun就认为,对于人类社会而言,有些事物是需要解释的,比如法律。但大多数情况下,其他事物的可解释性并没有想象中那么重要。LeCun又举了一个例子,他多年前和一群经济学家合作,做了一个预测房价的模型。第一个使用简单的线性猜测模型,能够清楚解释运作原理;第二个用的是复杂的神经网络,但效果比第一个更好。后来这群经济学家开了一家公司,他们会选择哪种模型?结果很明显。LeCun表示,任何一个人在这两种模型里选择,都会选效果更好的。
再者,通过政策条例和伦理准则提升算法透明度,依然存在一些局限性。要知道,要求算法具备可解释性与企业的利益可能会产生强烈冲突。简单公布一个模型的所有参数,并不能提供其工作机制的清晰解释。反而在某些情况下,透露太多算法工作原理的相关信息可能会让不怀好意的人攻击这个系统。
解释的可能性与必要性、信任与保密等多重张力之下,围绕可解释性问题的争议仍无定论,但一种共识正在逐渐达成,就是试图一网打尽的可解释性方法显然不具备可行性。没有一种模式能够适合所有问题,伴随算法技术的不断发展,可解释性工作的路径与方向也应该不断进行适应。
同样,AI可解释性不仅仅是一个技术原理的问题,也是技术伦理、社会意识的问题。Google也承认,它并不想使模型卡成为自身的一个产品,而是一个由多种声音构成的、共享的并且不断发展的框架,其中包括用户、开发人员、民间社会团体、行业公司、AI合作组织以及其他利益相关者。面对如此复杂的一个问题,AI的可解释性应该成为世界范围共同的目标与追求。图片
本文成稿于2020年11月,节选自《科技向善白皮书2021》。白皮书将于2021年中正式出版,敬请期待。

