




作者 | 王融 腾讯研究院资深专家
前 言
信任在社会财富创造和经济增长中扮演重要角色,在网络连接的数字社会中更是如此。腾讯研究院文章《经济增长的信任基础》结合区块链技术的应用与发展,探讨了塑造社会信任的正式制度(法律、监管、司法),以及非正式机制(社会风俗,伦理、技术)之间的相互关系。文章提出:科技应当与其他信任机制相互结合,用科技增强传统信任,才能走向更广阔天地。
本文将在此基础上继续讨论数字社会最重要的信任话题之一——隐私保护,该领域不仅再次验证了上述观点,还呈现了更为紧密的互动关系:隐私权迈向个人信息保护,是制度在回应信息技术带来的信任新风险,但制度不可避免具有滞后性。为减少规制惯性带来的负面效用,制度应保持适度弹性,以使制度与技术进行更包容的双向互动,彼此调整完善。在下一代人工智能新兴技术领域中,我们也欣喜地看到这种良性互动,以联邦学习(Federated Learning)为代表的AI技术方向,在保障隐私和数据安全的前提下,为进一步挖掘数据价值、创造社会福祉带来新的解决方案。
一、 制度对技术的回应:隐私权向个人信息保护扩展
回顾过去一百多年,在面对科技对个人安宁、自主性可能造成威胁时,制度均作出了积极的回应,并据此搭建监管框架,试图重建信任基石。
1890年,快速发展的八卦新闻业以及摄影技术应用对个人生活带来侵扰,美国学者由此提出了现代隐私权利理论[①],“个人独处的安宁”逐步被司法实践认可并成为法律原则。
到19世纪六七十年代,计算机大规模应用普及,防御性的、事后救济性的“隐私权”难以解决个人信息非法收集和利用问题,私法领域的“隐私权”逐步发展为公法领域的个人信息保护制度。即在未发生隐私侵害后果之前,就明确个人信息处理的方式,包括知情同意,最小化,目的特定、保障安全与可问责等。欧美发达国家率先完成个人信息保护立法。
进入21世纪,在应对云计算、大数据、物联网等带来的个人信息保护挑战中,欧盟扮演了领导者角色。《欧盟通用数据保护条例》(GDPR)细致规定了数据处理的合法性基础,并通过高额的违规处罚,促进了各行各业在数据保护方面的关注与投入,其在全球范围内形成立法示范效应,更是将数据保护推向了前所未有的重要性。
二、 制度的天然缺陷:滞后与规制惯性
如同其他领域的法律制度一样,隐私与个人信息保护立法过程,就是回应—滞后——再回应——再滞后的循环递进过程。
首先,个人信息保护制度的基石——“个人信息”定义一直处于被挑战状态。大数据的出现模糊了个人信息与非个人信息的边界。大量数据更易被关联和聚合,大大增强了将非个人信息转化为个人信息的能力。如果法律固守传统,适用于严格界定的“直接可识别身份的信息”,那么在大数据环境下,数据利用的安全风险又如何被规制?如果扩张个人信息的边界,那么又将扩张到何种程度,而不至于超出法律体系运行本身可负担的合理边界?这是实务中不断围绕cookie记录、搜索记录、动静态IP地址、设备编码是否属于个人信息争议的根源。随着物联网、智慧城市,甚至产业互联网的加速部署,将带来更多类似争议。网络上的信息日夜不分地紧密结合在一起,汇合成支撑社会运转的巨大信息流。在此情形下,将某一主体所提出的原信息从信息束的整体中独立拆分、收回(撤回)、取消或删除的难度日益加大,甚至在某种程度上,在原信息主体完全未知的情况下,它会自动在网络世界中互相进行联系、融合和更新[②]。
其次,个人信息保护基本原则难以应对新型的信息实践。各国现行的个人数据保护原则主要基于1980年《OECD个人数据保护指南》,而该指南形成的背景主要是针对六七十年代政府和大公司使用计算机收集和处理个人数据,因此确立了目的特定,知情同意,最小化等原则。但在当前以数据驱动的经济发展中,以上原则的适用已显得力不从心。过去:数据的收集往往在事前即可明确目的,当前:数据价值和创新依赖于后续的挖掘利用;过去:数据收集通过单个采集,知情同意机制尚可运转;当前:数据收集大多通过机器被动同步完成,围绕知情同意有效性的质疑不断增多;过去:政策监管框架聚焦于如何减少用户所面临的风险;当前:政策更多聚焦于如何在保护与促进创新、经济增长之间保持平衡。个人信息的使用与否不再取决于个人与与社会整体的交往、融入意愿,而是一种在多数情况下无须进行选择的生活方式、交往方式,这体现了社会运转方式的全局性、整体化变革[③]。
再次,区块链技术对现有个人信息保护实践带来了根本性的挑战。如果说移动互联网、云计算、大数据是对个人信息保护机制如何落地执行的挑战,GDPR尚可在体系内部进行修补,然而区块链的横空出世,则对个人信息保护规制范式带来根本性冲击。区块链创建了一种全新的信任机制,通过共识算法,去中心化分布式存储使参与者达成共识。这与个人信息保护机制建构的中心化规范范式不相适应[④]。传统个人信息保护制度体系重点指向的是现实世界里,中心化的数据控制者,例如:政府机构、银行、医院,以及各类互联网中心化平台。而在去中心化的区块链逻辑中,让分散在全球各节点(背后是个人或者机构)的参与者遵循统一的数据保护框架,对任何一家监管机构都充满挑战。更进一步,在区块链防止篡改的信任逻辑中,也很难支持数据保护制度中的更正权、删除权甚至是被遗忘权等权利诉求;单点记入、全网同步功能也与GDPR中的数据最小化原则格格不入。
尽管区块链与数据保护法律原则在底层逻辑上存在冲突,但不可否认,区块链的功能目标却与制度目标是兼容的。区块链有利于提升人们对个人数据的控制权,用户掌握着唯一的公钥和私钥,可以更为自由地选择将个人数据在何时披露给何人,相比之下,目前中心化的数据管理范式,如身份证号,医疗记录则有更多的被非授权披露的风险。
总之,当现有制度在尝试解决技术带来的问题时,往往会陷入规制的路径依赖,如在个人信息保护机制中,继续加强知情同意,继续加强个体权利,然而这些应对对于实际问题的解决似乎效果有限。正如欧盟GDPR在2016年甫一问世,制度规范就已走向固化。相比之下,技术发展却仍在以惊人的速度高歌猛进。在区块链之外,无人驾驶、面部识别、可穿戴设备、智能家居、医疗监测器械、行为生物数据、无人机等一个又一个技术应用,不断点燃数据驱动的新领域。对于这些新技术,是严格套用GDPR予以规范,还是适度平衡隐私保护与创新发展,是政策制定者无法回避的现实问题。
综上所述,现有的个人信息保护制度带有一定的缺陷。如果从区块链技术等新兴技术的发端开始,就将其完全套用在规制范围内,甚至视之为违法技术,那么无疑会扼杀实现数据保护目标和技术发展的一种可能。反之,更多采取宽容态度,将制度与技术进行更双向的包容互动,彼此调整和完善,将会是一个多赢的结果。正如欧盟理事会在GDPR实施一周年的评估报告中写道:“我们也应该看到技术在某些领域的应用也可能拥有巨大的优势,并有可能加强欧洲公民的隐私保护。”例如:基于区块链的“零知识证明技术”能够实现使用尽可能少的个人信息,同时验证某一特定主体的身份;[⑤]差异隐私技术能够实现数据集中而带来的价值,但同时保持特定自然人身份不被识别。[⑥]法律的适用应当为技术发展留有“一定空间”,而不是对技术的完全规训。这也许是欧盟数据保护委员会EDPB迟迟未就区块链出台合规指南的重要原因之一。
三、 制度也塑造和促进了隐私安全技术的发展
以欧盟GDPR为代表的个人数据保护制度促进了合规与隐私文化的发展,并推动业界用技术来解决隐私、安全问题。近年来,这个话题在学术界和和行业实践中都经历了爆炸性增长,包括:多方安全计算(Secure multi-Party Computation, MPC),同态加密(Homomorphic Encryption),差分隐私(Differential Privacy)等安全技术加速从理论走向实践,相关应用实践在金融、医疗、政务等领域渐次展开[⑦]。
基于大数据的机器学习既推动了AI蓬勃发展,也让AI在隐私安全这个方向上形成了新的分支——面向隐私保护的机器学习(Privacy-Preserving Machine Learning),其中又以联邦学习为代表。联邦学习正在广泛的跨学科领域获得吸引力:从机器学习到优化、信息理论和统计,再到密码学、公平性和隐私[⑧]。
(一) 隐私安全计算的新兴领域——联邦学习
尽管“数据是人工智能时代的石油”已经被作为广泛共识,然而现实中出于数据安全的担忧和隐私合规要求,各个机构主体掌握的数据是分散而碎片化的,数据往往难以在规模化基础上实现价值利用。在这种背景下,联邦学习作为一种行之有效的解决方案越来越引起更多关注。联邦学习可以使得各方在不披露原始数据的情况下达到共建模型的目的。即在不违反数据隐私保护法规的前提下,连接数据孤岛,通过算法实现数据价值利用。联邦的含义,是指各个数据的拥有体,大家之间是平等的,因此,联邦学习不仅着眼隐私保护,同时还致力于解决数据权属带来的数据利用激励问题。
“联邦学习”核心包括两个过程,分别是模型训练和模型推理[⑨]。在模型训练阶段,模型信息可以在各方交换,但数据不能交换。因此各方的数据安全以及基于权属的数据权益都可以得到保障;而在模型推理阶段,训练好的联邦学习模型可以放置于系统的各参与方,供多方共享。
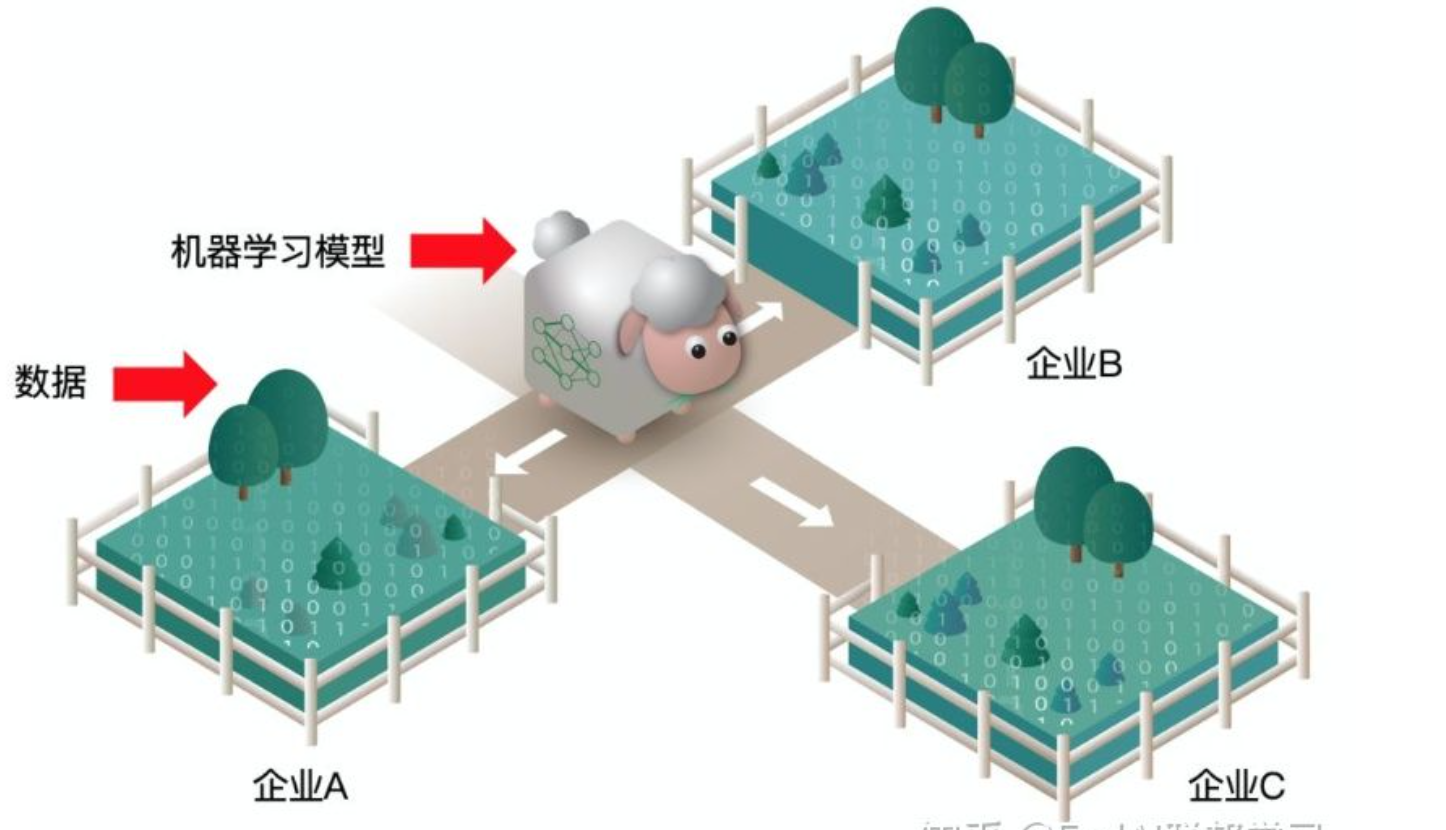
用联邦学习的布道者杨强教授提出的“羊吃草”例子来解释:在机器学习领域,模型效果的提升依赖于数据训练,所以机器学习模型就像一只小羊,而数据是草。在传统方法中,要建立机器学习模型,需要到各个草场(数据供应商)收购数据。但现实是:隐私和数据安全保护的要求使得获取数据成为障碍,草不能直接运出本地,这也就是我们常见的“数据孤岛”困境。
在此情况下,联邦学习提供了新的思路:让羊群在各地移动,而草不出本地。也就是机器学习模型以分布式的方式构建,而不需要数据在本地区域之外移动。这种“数据不动,模型动”的优势在于:对于每只羊的所有者而言,并不知道羊吃到肚子里的草到底是什么样,实现了在隐私保护和数据安全的前提下,机器学习模型不断完善。除了隐私保护和数据安全这一动机外,联邦学习的另一发展动力来自于最大化利用云系统下的终端设备的计算能力。
(二) 联邦学习——在保护用户隐私的前提下,让数据价值惠及个人
图片来源:https://zhuanlan.zhihu.com/p/141118286
2019年,谷歌在GoogleI/O 大会上展示G-Board应用,在TO C(消费者场景)中应用联邦学习技术,实现在隐私保护的前提下,更新迭代手机输入法预测模型[⑩]。在以往,由于手机本地输入会包含大量的用户隐私信息,因此无法将这些信息上传用于预测用户输入的智能输入法的模型训练。而通过联邦学习,每部安卓手机可以在本地训练模型,随后将模型参数上传汇总,从而帮助更快提升输入法的准确性。自2017年以来,苹果也一直利用差分隐私技术来发现最受欢迎的emoji表情,以及Safari 中的媒体播放项,并将其与联邦学习相结合,这两种技术都有助于改进苹果 Siri智能助理响应的准确性。
在TO C场景之外,联邦学习在B2B(企业到企业场景)中也大有可为。越是受到数据隐私和孤岛效应困扰的领域,越是联邦学习落地的最佳场景。典型包括:医疗、金融、教育、智慧城市等领域,在这些领域,联邦学习可以让数据价值真正惠及个人。例如[⑪]:
在医疗领域,英国国王学院组建“人工智能中心”,在英国国民医疗系统NHS的四家信托机构之间进行联合学习部署,使用这些超大型学习模型训练得以应用;英伟达医疗和MELLODDY合作,实现了在欧洲10家不同制药公司之间提供联合学习系统;腾讯天衍实验室联合微众银行研发的医疗联邦学习,在脑卒中预测的应用上,准确率在相关数据集中高达80%。通过应用联邦学习技术,医疗领域的数据福祉正在被探索开发。借助人工智能的数据分析,可以用来挽救生命,而且不必以牺牲个体隐私为代价。
在金融领域,平安科技公司正在研发建立全球首个面向金融行业的联邦学习平台“蜂巢”。“蜂巢”能够应用于多方信息的安全协作计算,满足银行和金融机构的风险评估、反洗钱、监管等多场景应用需求;微众银行通过多维度联邦数据建模,风控模型效果约可提升12%,相关企业机构有效节约了信贷审核成本,整体成本预计下降5%-10%,并因数据样本量的提升和丰富,风控能力进一步增强。
四、 技术与制度,如何形成互动式进步?
如何形成技术与制度之间的互动增强? 隐私与个人信息保护领域似乎正在形成一种参考:制度对待技术发展需要具有包容性,同时,技术本身在价值目标上也应与制度保持一致。
制度的包容性被证明很重要。人工智能、区块链等新技术都受到了GDPR的影响,但这并不意味着与制度互不兼容。在2018年5月GDPR生效之际,《终极算法》作者华盛顿大学教授 Pedro Domingos曾称:欧盟将会要求所有算法解释其输出原理,这意味着深度学习即将非法。对此,我们认为:GDPR确实对技术发展带来重大影响,但我们也无须将这种影响过分夸大,实际上欧盟29条工作组在2017年10月专门就此问题发布了指南明确澄清,关于自动决策,数据控制者并不必然要解释复杂的算法,对于用户来说,只需要用尽可能简单的方法告知其背后的基本逻辑或者标准即可。即使在最严格的欧盟,对包括区块链、人脸识别等人工智能应用,也并没有予以否定性评价。
而在另一面,技术也需与制度坚守同样的价值目标。正如联邦学习技术所展现的那样:在保障数据安全与隐私的前提下,实现数据共享,促进多源(元)数据的碰撞、融合,最大限度地释放数据价值[⑫]。
以联邦学习为代表的隐私安全技术与GDPR等数据保护制度所坚守的价值目标是一致的,甚至是后者推动了前者的发展。联邦学习需要满足数据保护制度要求,其完整的合规性框架至少应包括两个方面:
1)数据处理目的合法性。正如即使是合法的手段也不应当应用于非法目的一样,联邦学习的应用场景本身应是正当性的,例如在医疗领域的疾病分析与诊断,金融领域的信贷风险评估等。特别在医疗领域,数据汇聚分析对于人类福祉更有着极大价值。在TO C的其他应用场景中,如联邦学习方案最终应用于面向用户提供的个性化服务,也应向用户呈现相关逻辑,以保障用户知情权。
2)处理过程的合法性。其中包括模型(算法)隐私,以确保恶意行为者无法对训练数据进行反向工程;输入隐私,确保参与各方输入的算法参数不会被其他方观测到;输出隐私,保证除了应用最终结果的用户外,其他各方都看不到算法的最终输出。正如在TO C场景中,苹果应用差分隐私和联邦学习技术来对众多用户的个人数据进行了优化分析,并最终应用与用户有关个性化服务,整个过程中个体用户的数据不会被其他方观察到,但最终每位用户都享受到了数据汇聚分析后的便利和效率提升。在通过数据实现“我为人人,人人为我”的价值创造过程中,不以牺牲个人隐私为代价。
当然,没有任何技术是没有缺陷的,联邦学习同样需要在实践中不断完善,并推进隐私保护各技术领域的进步,只要其始终与制度价值目标保持一致。
结 语
在迈向数字社会的转型过程中,我们比任何时刻都更加渴望信任。过去一百年的信息技术进步与制度回应的实践,让我们更加清晰地看到:构建数字社会的信任基石,需要在正式与非正式的信任机制之间形成凝聚互动,而不是仅仅依靠其中一种。单一强调伦理,则无法避免杀熟现象;完全依赖法规监管,便要承受抑制创新发展结果;技术万能论更是早已破灭的神话。数字社会的信任构建,需要学术(理论和工程)、商业实践、社会治理拧麻花般的协作共建。
正如美国政府2014年关于大数据的第一份白皮书——《抓住机遇、坚守价值》中指出:大数据分析所拥有的潜力,将逐步侵蚀长久以来在公民权利保护方面的形成的价值基石,但大数据本身也蕴藏着解决信任、隐私、公民权利保护等方面的潜力。如果运用得当,大数据将成为推动社会进步历史性的助推器。因此,公民与数据的关系应当扩展,而不是压缩,以抓住这一历史性机遇和潜能。拥抱大数据,同时最大程度地保护人们在隐私、公平、自觉方面的价值基础。
参考文献:
[①] Samuel D. Warren & Louis D. Brandeis, The Right to Privacy, 4 HARV. L. REV.193 (1890). It defines the right to privacy as the “right to be let alone,” in areaction to the development of journalism and gossip columns.
[②]民法典工作项目组 与民法典同行,《大数据时代下个人信息保护的立法模式变革》,2018年2018-03-07
[③]引用同上。
[④] Michèle Finck,Blockchains and Data Protection in the European Union,Max Planck Institute for Innovation and Competition Research Paper No. 18-01
[⑤]零知识证明技术指的是证明者能够在尽可能少向验证者提供甚至不提供任何有用的信息的情况下,使验证者相信某个论断是正确的。AHN Gail-Joon, “Zero-knowledge proofs of retrievability”, Science China (Information Sciences), Vol.10(8), 2011, pp.1608-1617.
[⑥]差异隐私技术指的是从统计数据库查询时,最大化数据查询的准确性,同时最大限度减少识别其记录的机会,这种机制的核心是给查询的结果增加一定的噪点。Mannhardt, Felix, “Privacy-Preserving Process Mining”, Business & information systems engineering, Vol.61(5), 2019, pp.595-614.
[⑦]中国信息通信研究院云计算与大数据研究所,《多方安全计算技术与应用研究报告》,2019年12月
[⑧] Peter Kairouz and H. Brendan McMahan conceived, coordinated, and edited this work. Correspondence to kairouz@
google.com and mcmahan@google.com.,Advances and Open Problems in Federated Learning,
[⑨]杨强,刘洋等著,《联邦学习》,中国工信出版社,2020年4月出版,第4页。
[⑩] https://www.businessinsider.com/google-io-live-blog-all-announcements-coverage-updates-2019-5
[⑪]王健宗:数据隐私保护新曙光——联邦学习的机遇,挑战与未来,《联数》,第1卷,第8期,2019年7月22日。
[⑫]梅宏,在《联邦学习》一书中的推荐语,中国工信出版社,2020年4月出版。

