



Algorithms are mirrors that maps many inherent biases in human society.
In 2014, Amazon engineers set out to develop an artificial intelligence recruiting software that uses algorithms and data analysis to screen candidates to avoid the “emotional” problems peculiar to human recruiters. However, the software avoids the problem of “emotional” problem but makes an even bigger mistake with “bias” – the software engineers write the human recruiter’s screening patterns into the algorithm, and real-world biases are brought into the machine unconsciously.
With the increasing popularity of intelligent technology, algorithm decision making has become a trend. Avoiding the biases of human society mapped into the algorithmic world is an important proposition in today’s digital existence.
Previously, AI&Society’s column published: “Algorithmic Bias: The Invisible ‘Ruler’” attempted to dissect the problems posed by algorithmic bias, and this article focused on current solutions to algorithmic bias.
In the process of machine learning, the algorithm bias would be permeated from three links: the lack of representation in the composition of the data set, the engineer making algorithmic rules, and the marker handling unstructured material.
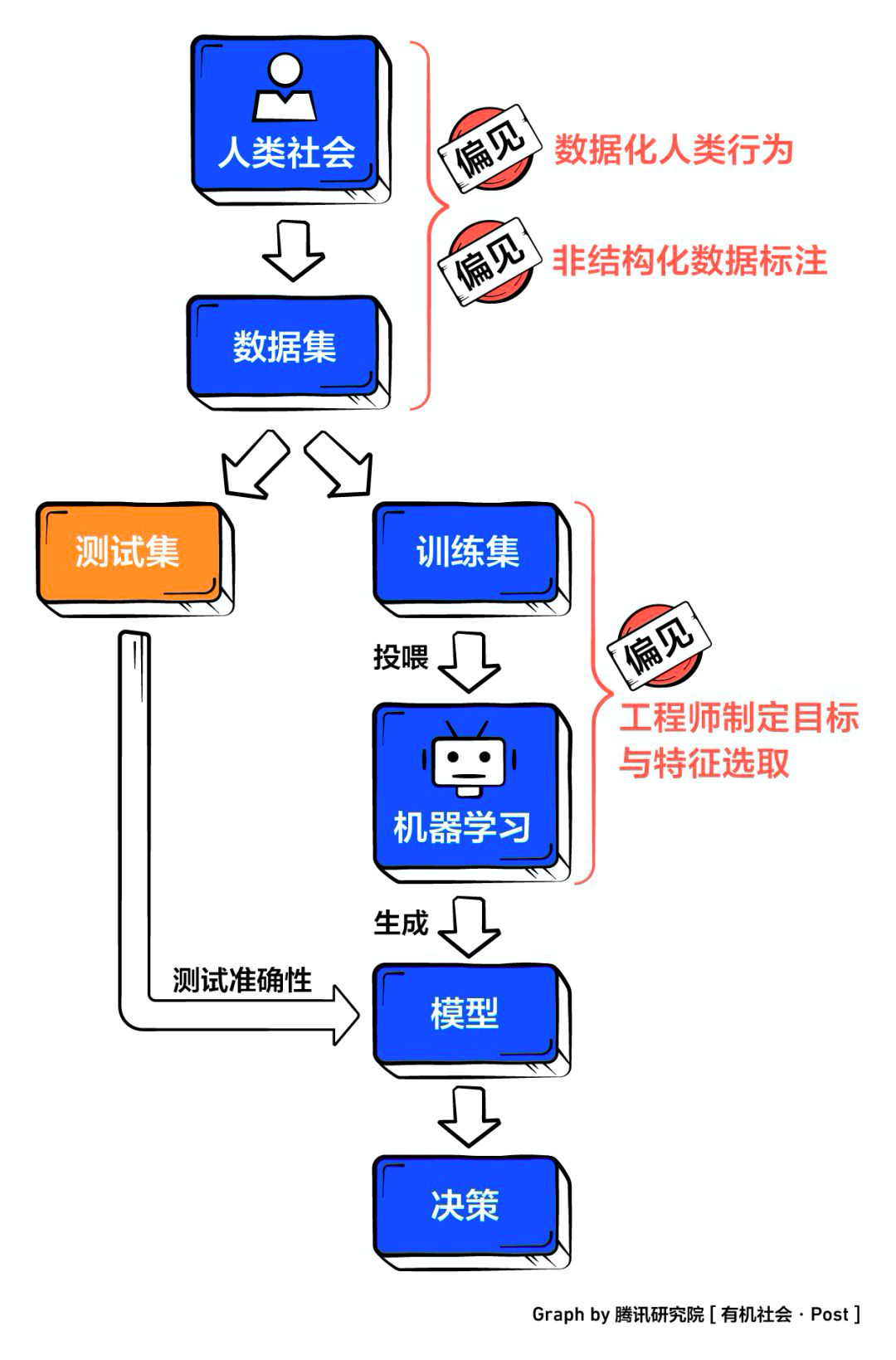
“After surveying 500 engineers in the machine learning field, it was concluded that one of the biggest problems machine learning engineers face today is that they know something has gone wrong, but they don’t know exactly where it went wrong and or why it was wrong.” said Harry Shum, a former executive vice president at Microsoft.
The unknowable, untraceable nature of algorithmic bias makes the task of counter-bias tricky. Under the existing response system, whether policy regimes, technological breakthroughs or innovative countermeasures, attempts have been made from different perspectives to address this problem, which has moved beyond technology.
First Solution: Build More Just Data Sets
Unfair data sets are the soil of prejudice – if the dataset used to train machine learning algorithms do not represent objective realities, the results of this algorithm’s application tend to be discriminatory and biased against specific groups. Therefore, the most straightforward way to address algorithmic bias is to adjust the original unbalanced data set.
Fix Data Proportion: Use a fairer data source to ensure decision-making is fair. In June 2018, Microsoft worked with experts to fix and extend the data set used to train the Face API, an API in Microsoft Azure that provides pre-trained algorithms to detect, recognize, and analyze attributes in face images. The new data reduced the identification error rate between darker-skinned men and women by a factor of 20 and women by a factor of 9, by adjusting for the proportion of skin color, gender and age. There are also companies that try to optimize data sets by building global communities. Large-scale integration of any information that an organization may be looking for through global communities and in a combination of breadth and depth makes it possible to train an AI system with disparate data, in order to help overcome problems such as algorithm bias.
Combination of “big data” and “small data”: Ensure accuracy based on data volume. Data sets should not be limited to extensive collection, but rather to precise mastery. Making an essay on the amount of data alone often does not lead to more fair results, as big data analysis focuses on relevance, leading to errors in the derivation of causal relationships. The introduction of small data can partially solve this problem. Small data refers to the form of data focused on the individual user, with more attention to detail and differences, and can present more accurate data and avoid errors in the derivation of cause-effect relationships. So, combining information-rich big data with information-accurate small data can avoid errors to a certain extent.
Autonomous test datasets: Detecting bias in the dataset. Scientists at the Massachusetts Institute of Technology’s Computer Science and Artificial Intelligence Laboratory (MIT SCAIL) published a paper titled “Uncovering and Mitigating Algorithmic Bias through Learned Latent Structure,” demonstrating that DB-VEA (an AI system for unsupervised learning) can automatically eliminate data bias through resampling. The model learns not only facial features (e.g., skin color, hair) but also other features such as gender and age, so classification accuracy increases significantly and classification bias against race and gender decreases significantly.
From this, building more impartial datasets is undoubtedly one of the fundamental solutions to algorithmic bias, and is the direction in which many companies, scholars are working, and there are indeed breakthroughs in this area at present.
Second Solution: Improve “Algorithmic Transparency”
Although algorithmic models are written by engineers, many times humans do not understand the process a computer goes through to arrive at a particular result, which is the “algorithmic black box” problem in machine learning. Therefore, enterprises are required to improve the transparency of the algorithm model, from which to find the “cause” of bias, has become one of the ways to solve the “black box” dilemma. Whether it is through policies, “other laws” of terms, ethical “self-regulation” of enterprises or technological exploration, the focus is constantly on opening the “black box” when combating algorithmic bias.
Self-regulation: an ethical proposition for business
In the past two years, many large tech companies have released principles for the application of AI, all of which involve a section on bias governance, and such principles can be seen as a statement of the tech company’s position and a starting point for self-regulation. Microsoft, Google, and IBM, all emphasize the transparency and fairness of their algorithms. It is noteworthy that Microsoft has created the Artificial Intelligence and Ethical Standards (AETHER) committee to implement its principles and plans to subject every AI product launched in the future to an AI ethics review.
There are also enterprises that use mechanisms other than committees. Google also responded to the increased transparency by introducing the Model Cards feature, which resembles an algorithm specification, explaining the algorithm used, informing about its advantages and limitations, and even the results of calculations in different data sets.
Laws: transparency and justice for results in the oversight process
The EU General Data Protection Regulation (GDPR), which came into force on May 25, 2018, and the UK government’s updated Data Ethics Framework on August 30, 2018, require a certain level of openness, transparency, and interpretability in algorithms. on April 10, 2019, members of both houses of Congress introduced the Algorithm Accountability Act, which requires large technology companies to assess the impact of their automated decision-making systems and eliminate any bias therein based on differences in race, color, religion, political belief, gender, or other characteristics.
Recognizing the dangers of algorithmic bias, some public interest organizations have also helped companies establish mechanisms to guarantee algorithmic justice. The Algorithm Justice League encapsulates and condenses the behaviors that businesses should follow into signable agreements to improve existing algorithms in practice by holding those who design, develop, and deploy algorithms accountable, and examining businesses to enhance outcomes. And the device did serve as an urging for algorithmic correction: its founder Joy Buolamwini fed back the results after evaluating IBM’s algorithm, and within a day received a response from IBM saying it would fix the problem. Later, when Buolamwini re-evaluated the algorithm, he found that IBM’s algorithm had a significant improvement in its accuracy for minority facial recognition: the accuracy rate for identifying dark males jumped from 88% to 99.4%, and for dark females from 65.3% to 83.5%.
“Algorithmic transparency” isn’t a perfect answer?
However, there are still some limitations to improving algorithmic transparency through policy regulations and ethical guidelines. First, the requirement that the algorithm be interpretable creates a strong conflict with the interests of the possible enterprise. Rayid Ghani, director of the Center for Data Science and Public Policy at the University of Chicago, argues that simply publishing all the parameters of a model does not provide an explanation of its working mechanism and in some cases, revealing too much information about how the algorithm works may allow unsuspecting people to attack the system.A December 2019 paper also notes that variants of LIME and SHAP, the two technologies that explain black box algorithms, are at risk of being hacked, meaning that “interpretations made by AI may be deliberately tampered with, leading to a loss of trust in the model and the interpretations it gives”.
Second, the heart of the Accountability Act is to enable businesses to investigate and correct themselves. But this top-down system undoubtedly adds a huge amount of workload to firms, and in a round of review assessments, technological progress will be hampered and firms’ innovativeness will be compromised.
Third Solution: Technological Innovation Against Bias
When bias is hidden in countless codes, engineers think about solving technical problems with the technology itself. This approach does not begin with the source of the bias, but rather makes creative use of technological means to detect and dismantle it.
Word embedding addresses gender bias in search: Microsoft researchers looked at text from news, web data and found that words showed some distinct characteristics when making associations, such as words like “sassy” and “knitting” being closer to women and “hero” and “genius” being closer to men. The reason for this is that the baseline data sets used to train the algorithms – often from news and web pages – are themselves “gender biased” by linguistic conventions, and the algorithms naturally “inherit” gender differences in human understanding of these terms. Microsoft has proposed a simple and easy solution: remove the judgment dimension that distinguishes between “he” and “she” in the word embedding and use it to reduce the “display of bias”. Of course, this “simple and brutal” approach can only be used in the text search field, and in more practical scenarios, the “black box” nature of AI makes it difficult to complete the elimination of bias through direct deletion by linking gender or race to more complex parameters.
Exposing system flaws through differential testing: Researchers at Columbia University have developed software called DeepXplore that can “trick” systems into making mistakes to expose flaws in algorithmic neural networks. DeepXplore uses differential testing, a concept that compares multiple different systems and looks at their corresponding output differences: DeepXplore looks at things differently, and if other models all make consistent predictions for a given input, but only one model makes a different prediction about it, then that model is judged to have a flaw. This study makes an important contribution to unlocking the black box, as it can expose countless possible problems in the algorithm by activating almost 100% of the neural network.
Bias Detection Tool: In September 2018, Google launched a new tool, What-If, which is the tool used to detect bias in TensorBoard. With this tool, developers can explore the importance of features of machine learning models through interactive visual interfaces and counterfactual reasoning, identify causes of misclassification, determine decision boundaries, and detect algorithmic fairness. Similarly, IBM has made its bias detection tool, the AI Fairness 360 Toolkit, open source, which includes more than 30 fairness metrics and nine bias mitigation algorithms that researchers and developers can integrate into their own machine learning models to detect and reduce the bias and discrimination that can arise.
Technology itself is used to combat bias and is a highly actionable approach because engineers tend to be good at solving real problems with technology. However, judging from the results so far, most of the technological breakthroughs are still in their infancy and remain at the stage of detecting bias, the elimination of which may be left to the next phase of efforts.
At the end
The causes of prejudice in real society are intertwined, and the campaign to eradicate prejudice continues unabated and has yet to be eradicated. At present, prejudice is a digital memory, cunningly and insidiously hidden in every unsuspecting double whammy, every tiny decision, yet it can significantly affect the way people are treated.
More impartial data sets, more timely error detection, more transparent algorithmic processes… A concerted effort by tech companies, research institutions, regulators, and third-party organizations to declare war on algorithmic bias. These initiatives do not necessarily eliminate prejudice altogether, but they do much to prevent technology from infinitely amplifying the prejudices inherent in society.
Rather than blaming the algorithm bias entirely on technology, it is more important to realize that technology, as a tool, should be applied with boundaries that penetrate into the depth of everyday life, the extent to which decision-making is adopted, and that prudent decision-making is needed.
References:
1.《沈向洋就职清华演讲全录:人类对AI如何做决定一无所知》AI前线https://mp.weixin.qq.com/s/sezAachD_dhB3wrDTTZ8ng
2.《算法偏见就怪数据集?MIT纠偏算法自动识别「弱势群体」 》机器之心
https://www.jiqizhixin.com/articles/2019-01-28-11
3.《Applause推出新AI解决方案 致力于解决算法偏见》网易智能 https://mp.weixin.qq.com/s/oG9GtlplwXrNkGnXqEZOWA
4.《“算法有偏见,比人强就行?”其实影响很广泛!》THU数据派
https://mp.weixin.qq.com/s/_ArUXZGT6_iJ_Nggrit8-A
5.《算法偏见侦探》 雷锋网AI 科技评论
https://www.leiphone.com/news/201812/b4FLYHLrD8wgLIa7.html
6.《沈向洋:微软研究院——求索不已,为全人类,打造负责任的人工智能》 微软科技https://www.sohu.com/a/337918503_181341
7.《DeepXplore:深度学习系统的自动化白盒测试》 AI前线
https://mp.weixin.qq.com/s/ZlVuVGW_XA_MTgBJhMmqXg

