




算法是一面镜子,映射了人类社会许多固有的偏见。
2014年,亚马逊的工程师着手开发一款人工智能招聘软件,利用算法和数据分析来筛选候选人,以此避免人类招聘官身上特有的“感情用事”问题。事与愿违,这款软件虽避免了“感情用事”问题,却在“偏见”上犯下更大的错误——软件编写者将人类招聘官的筛选模式写入算法,现实世界中无意识的偏见也带进了机器。
随着智能技术的不断普及,算法做决策成为趋势。避免人类社会的偏见映射到算法世界中,是当下数字化生存中的重要命题。
此前,AI&Society专栏发布的《算法偏见:看不见的“裁决者”》试图剖析算法偏见所带来的问题,本文着重梳理当前针对算法偏见的一些解决方案。
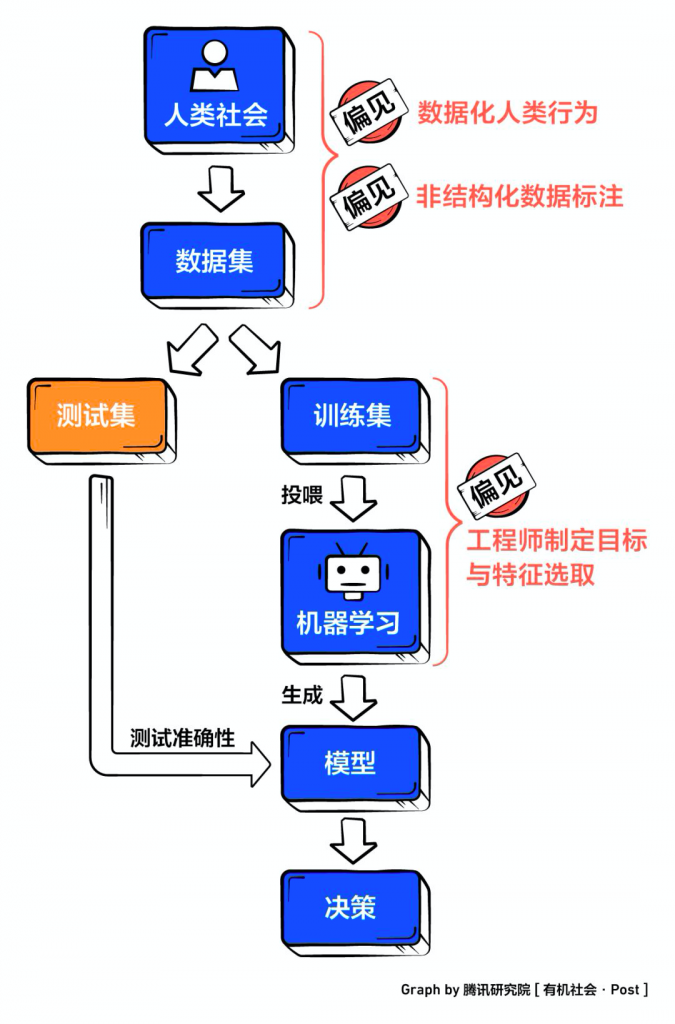
在机器学习过程中,算法偏见会从三个环节中被渗透:数据集的构成缺乏代表性,工程师制定算法规则时、打标者处理非结构化素材,都有可能混入偏见。
在对500名机器学习领域工程师调查后得出结论:如今机器学习工程师面临的最大问题之一是他们知道出了一些问题,但是不知道具体是哪里出了问题,也并不知道为什么会出现问题。”前微软公司执行副总裁沈向洋指出。
由于算法偏见的不可知、不可查,让反偏见这项工作变得棘手。在现有应对体系下,无论是政策制度、技术突破还是创新型反制,都从不同的角度出发尝试解决这个已经超越技术的问题。
解决思路一:构建更公正的数据集
不公正的数据集是偏见的土壤——如果用于训练机器学习算法的数据集无法代表客观现实情况,那么这一算法的应用结果往往也带有对特定群体的歧视和偏见。因此,算法偏见最直接的解决思路就是将原本不均衡的数据集进行调整。
修正数据比例:利用更公平的数据源确保决策公正性。2018年6月,微软与专家合作修正和扩展了用于训练 Face API 的数据集。Face API 是微软 Azure 中的一个 API,它提供预训练算法以检测、识别和分析人脸图像中的属性。新数据通过调整肤色、性别和年龄等所占的比例,将肤色较深的男性和女性之间的识别错误率降低 20 倍,女性的识别误差率降低 9 倍。也有公司尝试通过构建全球社区的方式优化数据集。通过全球社区,大规模地把某个组织可能在寻找的任何信息汇集起来,并以这种广度和深度相结合的方式进行,这使得引入截然不同的数据来训练AI系统成为可能,以帮助克服算法偏见等问题。
“大数据”与“小数据”结合:在数据量的基础上确保精度。数据集不应局限于粗放收集,而在于精准把握。仅仅在数据的量上做文章往往不能带来更加公正的结果,因为大数据分析侧重相关性,导致在推导因果关系时容易出现误差。引入小数据可以部分解决这个问题。小数据指聚焦于用户个体的数据形态,它更关注细节,重视差异,能更呈现更加准确的数据,也避免推导因果关系时出现误差。所以,将信息丰富的大数据与信息精准的小数据相结合可在一种程度上避免误差。
自主测试数据集:侦测数据集中偏见。麻省理工学院算机科学与人工智能实验室(简称MIT SCAIL)的科学家发表了一篇题为《Uncovering and Mitigating Algorithmic Bias through Learned Latent Structure(通过学习潜在结构提示并缓解算法偏见)》的论文,展示了DB-VEA(一种无监督式学习)可以通过重新采样来自动消除数据偏见的 AI 系统。该模型不仅学习面部特征(如肤色、头发),还学习诸如性别和年龄等其它特征,所以分类准确率明显增加,且针对种族和性别的分类偏见明显下降。
由此可见,构建更加公正的数据集无疑是算法偏见根本性的解决方法之一,也是许多企业、学者努力的方向,并且目前在这一领域的确有所突破。
解决思路二:提升“算法透明度”
尽管算法模型由工程师编写而成,但很多时候,人类并不明白计算机经历了怎样的过程才得出某一特定结果,这就是机器学习中的“算法黑箱”问题。因此,要求企业提高算法模型的透明度,从中找出偏见“病因”,就成为了当下解决“黑箱”困境的途径之一。无论是通过政策、条款的“他律”,还是企业通过伦理“自律”还是技术探索,在对抗算法偏见时,都持续聚焦于打开“黑箱”。
自律:企业的伦理主张
在过去两年中,许多大型科技公司都发布了人工智能的应用原则,其中均涉及到偏见治理的部分,可以将这类原则视为科技公司立场的声明和自律的起点。微软、谷歌和IBM,均强调算法的透明性和公平性。值得说明的是,微软设立人工智能与道德标准(AETHER)委员会来落实其原则,并计划未来推出的每一个人工智能产品都要经过人工智能道德伦理审查。
也有企业采用委员会之外的机制。谷歌推出Model Cards功能也是对提升透明度的回应。Model Cards类似算法说明书,对采用的算法进行解释,告知其优点和局限性,甚至在不同数据集中的运算结果。
他律:监督过程透明与结果正义
2018年5月25日正式生效的《欧盟一般数据保护条例》(GDPR),2018年8月30日英国政府更新的《数据伦理框架》,要求算法需要具备一定的公开性、透明性与可解释性。2019年4月10日,美国国会两院议员提出《算法问责法案》,要求大型科技公司评估其自动决策系统带来的影响,并消除其中因种族、肤色、宗教、政治信仰、性别或其它特性差异而产生的偏见。
一些公益组织也因意识到算法偏见的危害性,帮助企业建立机制保障算法公正。算法正义联盟(Algorithm Justice League)将企业应遵守的行为概括和浓缩成了可以签署的协议,通过问责算法的设计、开发和部署者,在实践中改善现有算法,并检查企业提升成果。而这一手段的确为算法纠偏起到了敦促作用:其创始人Joy Buolamwini在评估IBM算法后将结果反馈,并在一天内收到了IBM回应称会解决这一问题。之后当Buolamwini重新评估该算法时,发现IBM的算法对于少数群体面部识别的准确率有了明显提升:识别深色男性的准确率从88%跃升至99.4%,深色女性的准确率从65.3%升至83.5%。
“算法透明”不是满分答案?
然而,通过政策条例和伦理准则提升算法透明度,依然存在一些局限性。首先,要求算法具备可解释性与可能企业的利益产生强烈冲突。芝加哥大学数据科学与公共政策中心主任 Rayid Ghani认为,简单地公布一个模型的所有参数并不能提供对其工作机制的解释在某些情况下,透露太多关于算法工作原理的信息可能会让不怀好意的人攻击这个系统。2019年12月的一篇论文也指出,解释黑箱算法的两大技术LIME和SHAP的变体有可能遭到黑客入侵,这意味着“AI做出的解释可能被蓄意篡改,导致人们对模型及其给出的解释失去信任”。
第二,问责法案的核心在于促成企业自查自纠。但这种自上而下的制度无疑为企业增加了巨额工作量,在一轮轮审查评估中,技术进度将受到掣肘,企业的创新力也会被影响。
解决思路三:技术创新反偏见
当偏见被隐藏在无数代码中时,工程师们想到用技术本身解决技术问题。这一途径并非是从偏见来源入手,而是创造性地利用技术手段侦测偏见、解除偏见。
单词嵌入解决搜索中的性别偏见:微软研究人员从新闻、网页数据中的文本,发现词汇之间在建立关联时表现出一些明显特征,例如“sassy(刁蛮)”、“knitting(编织)”这样的词更靠近女性,而“hero(英雄)”、“genius(天才)”更靠近男性。之所以会有这种现象,原因在于训练算法用的基准数据集——通常是来自新闻和网页的数据——本身,就存在着由语言习惯造成的“性别偏见”,算法也自然“继承”了人类对这些词汇理解的性别差异。微软提出了一个简单易行的方案:在单词嵌入中,删除区分“他”和“她”的判断维度,用于降低“偏见的展示”。当然,这样“简单粗暴”的方式只能运用在文本搜索领域,在更多实际应用场景下,人工智能的“黑箱”特性使性别或种族与更多更复杂的参数相勾连,因此很难通过直接删除来完成偏见的剔除。
通过差分测试(differential testing)暴露系统缺陷:哥伦比亚大学的研究者开发了一款名为DeepXplore的软件,它可以通过“哄骗”系统犯错,以暴露算法神经网络中的缺陷。DeepXplore使用了差分测试(differential testing),一种比较多个不同系统并查看它们对应输出差异的概念:DeepXplore以不同的方式看待事物,如果其他模型都对给定的输入做出一致的预测,而只有一个模型对此做出了不同的预测,那么这个模型就会被判定有一个漏洞。这一研究为打开黑箱做出了重要的贡献,因为它可以通过激活几乎100%的神经网络,来曝光算法中可能出现的无数个问题。
偏见检测工具:在2018年 9 月,谷歌推出了新工具 What-If,这是 TensorBoard 中用于检测偏见的工具。利用该工具,开发者可以通过交互式可视界面和反事实推理探究机器学习模型的特征重要性,找出误分类原因、确定决策边界,以及检测算法公平性等。同样,IBM也将其偏见检测工具AI Fairness 360 工具包开源,其中包括超过 30 个公平性指标和 9 个偏差缓解算法,研究人员和开发者可将工具整合至自己的机器学习模型里,检测并减少可能产生的偏见和歧视。
技术本身被用于打击偏见,是一种可操作性极强的方法,因为工程师们往往擅长于用技术解决实际问题。但是从目前的成果来看,大多技术突破还仅处于初级阶段,停留在检测偏见,消除偏见可能还待下一阶段努力。
写在最后:
现实社会中的偏见产生的原因盘根错节,致力于消除偏见的运动绵延不息,也尚未彻底将其消灭。眼下,偏见化身为数字记忆,狡黠又隐蔽地藏身于每一次不经意的双击,每一个微小的决策,却能显著影响人们被对待的方式。
更公正的数据集,更及时的误差检测,更透明的算法过程……科技公司、科研机构、监管部门以及第三方组织的协同努力对算法偏见宣战。这些举措未必彻底消除偏见,但能极大避免技术无限放大社会固有的偏见。
相比将算法偏见全然怪罪于技术,更重要的是意识到,技术作为一种工具,应用应有边界,它渗入日常生活的深度、决策被采纳的程度,需审慎决策。
参考资料:
1.《沈向洋就职清华演讲全录:人类对AI如何做决定一无所知》AI前线https://mp.weixin.qq.com/s/sezAachD_dhB3wrDTTZ8ng
2.《算法偏见就怪数据集?MIT纠偏算法自动识别「弱势群体」 》机器之心
https://www.jiqizhixin.com/articles/2019-01-28-11
3.《Applause推出新AI解决方案 致力于解决算法偏见》网易智能 https://mp.weixin.qq.com/s/oG9GtlplwXrNkGnXqEZOWA
4.《“算法有偏见,比人强就行?”其实影响很广泛!》THU数据派
https://mp.weixin.qq.com/s/_ArUXZGT6_iJ_Nggrit8-A
5.《算法偏见侦探》 雷锋网AI 科技评论
https://www.leiphone.com/news/201812/b4FLYHLrD8wgLIa7.html
6.《沈向洋:微软研究院——求索不已,为全人类,打造负责任的人工智能》 微软科技https://www.sohu.com/a/337918503_181341
7.《 DeepXplore:深度学习系统的自动化白盒测试》 AI前线
https://mp.weixin.qq.com/s/ZlVuVGW_XA_MTgBJhMmqXg
AI&Society是腾讯研究院推出的跨界讨论与行动平台。我们尝试通过【AI&Society专栏】这一工具,梳理当下AI与社会的动向和议题,迎接思考者与关心者,为后续讨论与行动打下基础。

